几款顺手的小工具,帮你把事情更快做完
视频压缩、图片压缩、视频消音、字幕识别、音频合并、图像处理、智能抠图、会议转录、数据洞察、智能剪辑,打开就能用。少一点折腾,多一点省心。
常用场景都能覆盖
从视频、音频到会议整理,一套工具帮你处理日常高频需求。
文件更安心
素材在本地处理,不上传服务器,隐私内容自己掌握。
打开就能上手
界面简单直接,不需要复杂学习,第一次用也能很快找到功能。
省时间,也省心
把重复、琐碎的处理工作交给工具,你可以把时间留给更重要的事。
选一款开始
先看看界面和主要功能,再选择最适合你的那一款。
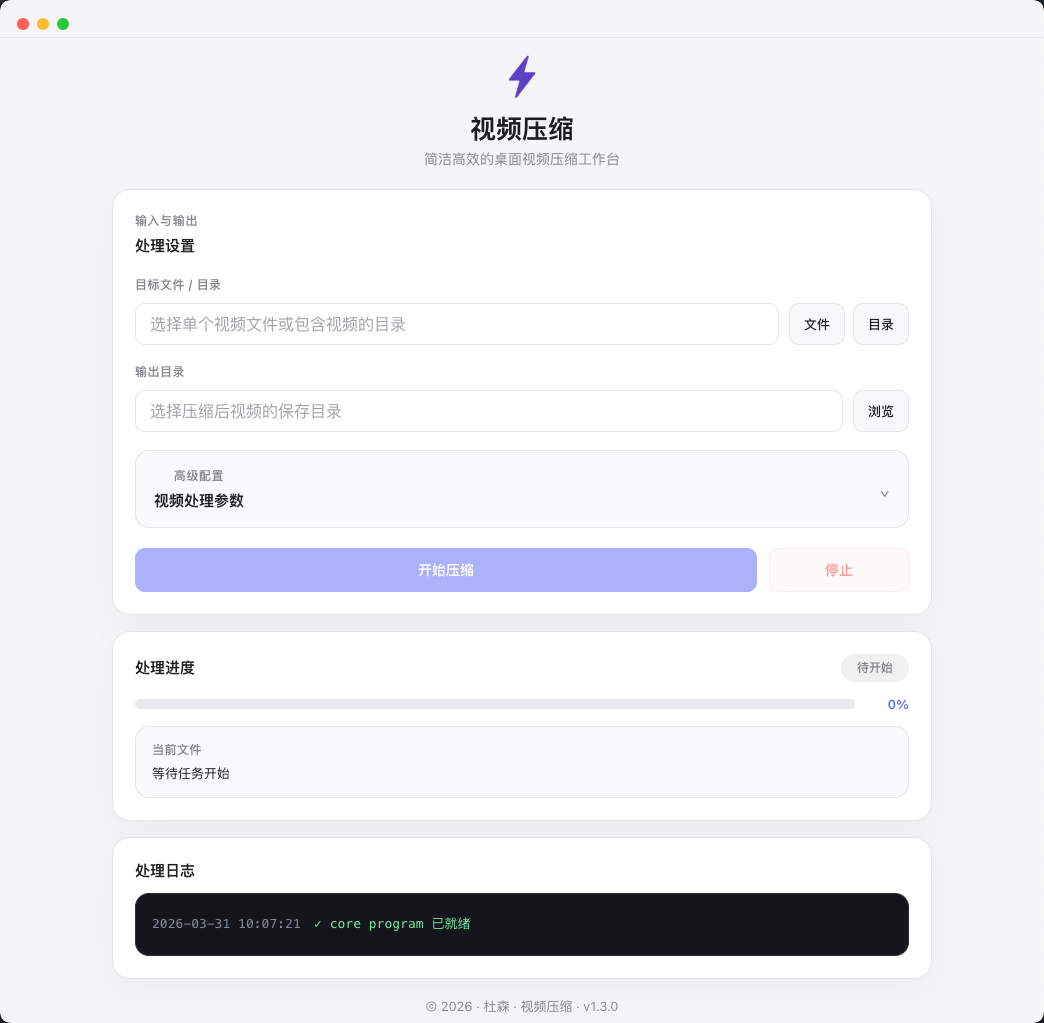
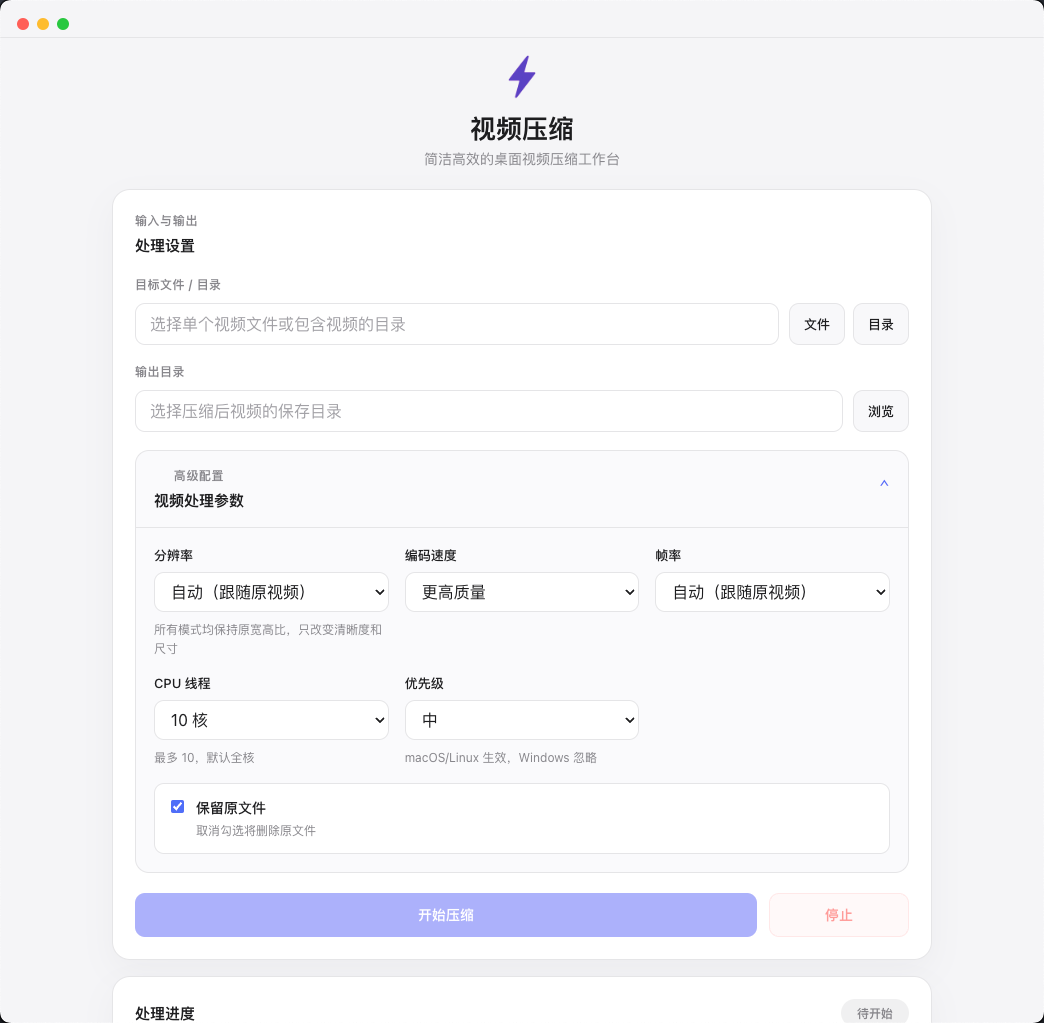
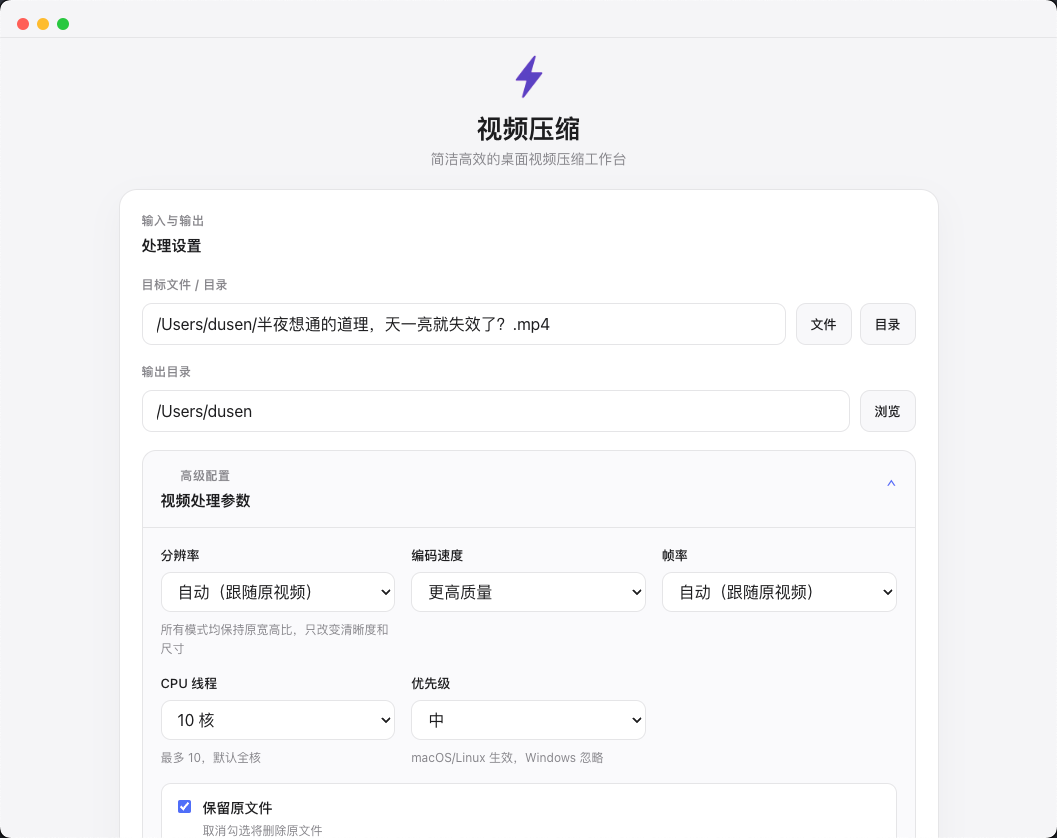
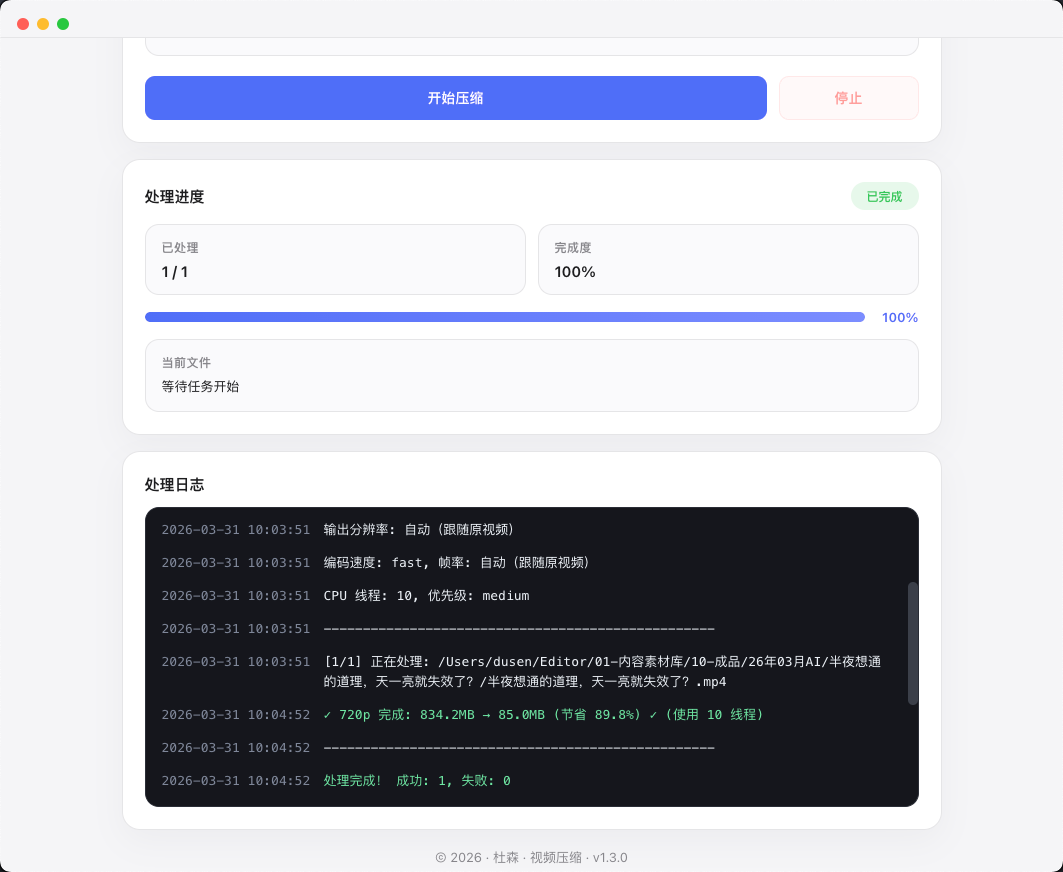
视频压缩
极致压缩,尽量保住画质。支持 4K / 1080p / 720p 多种分辨率,批量处理大文件,适合需要快速导出和归档的视频工作流。
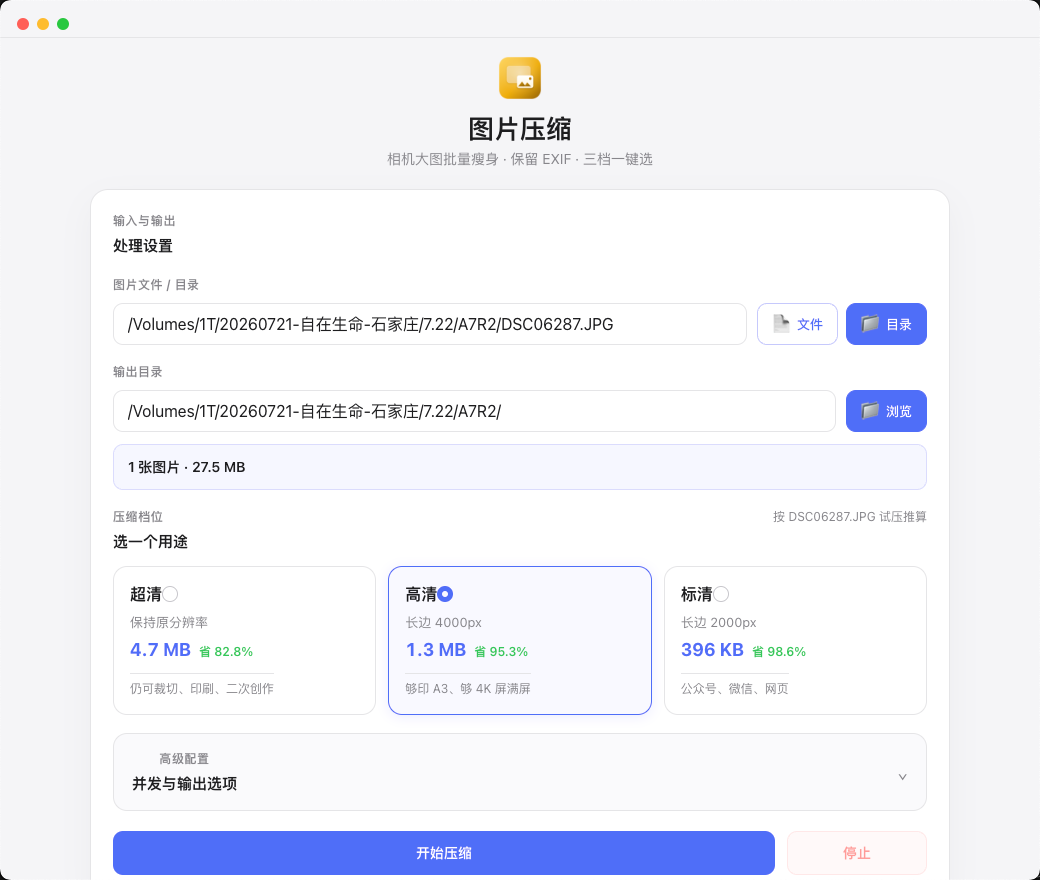
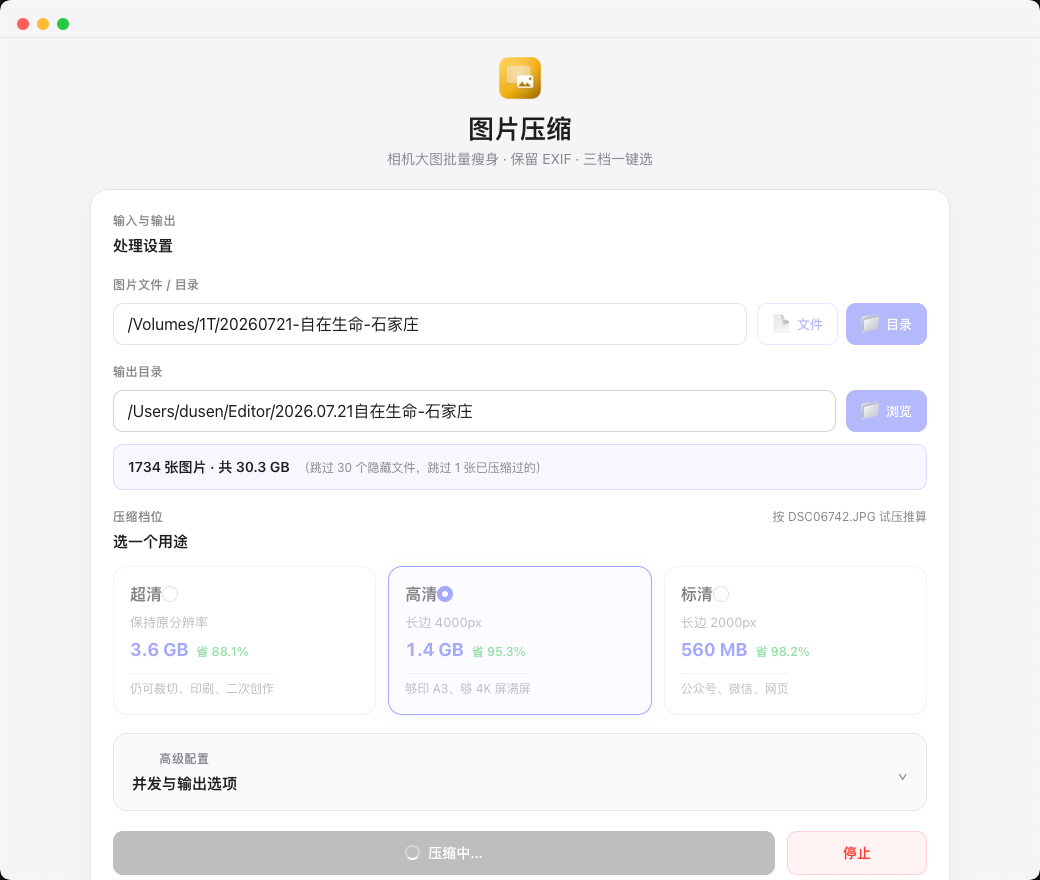
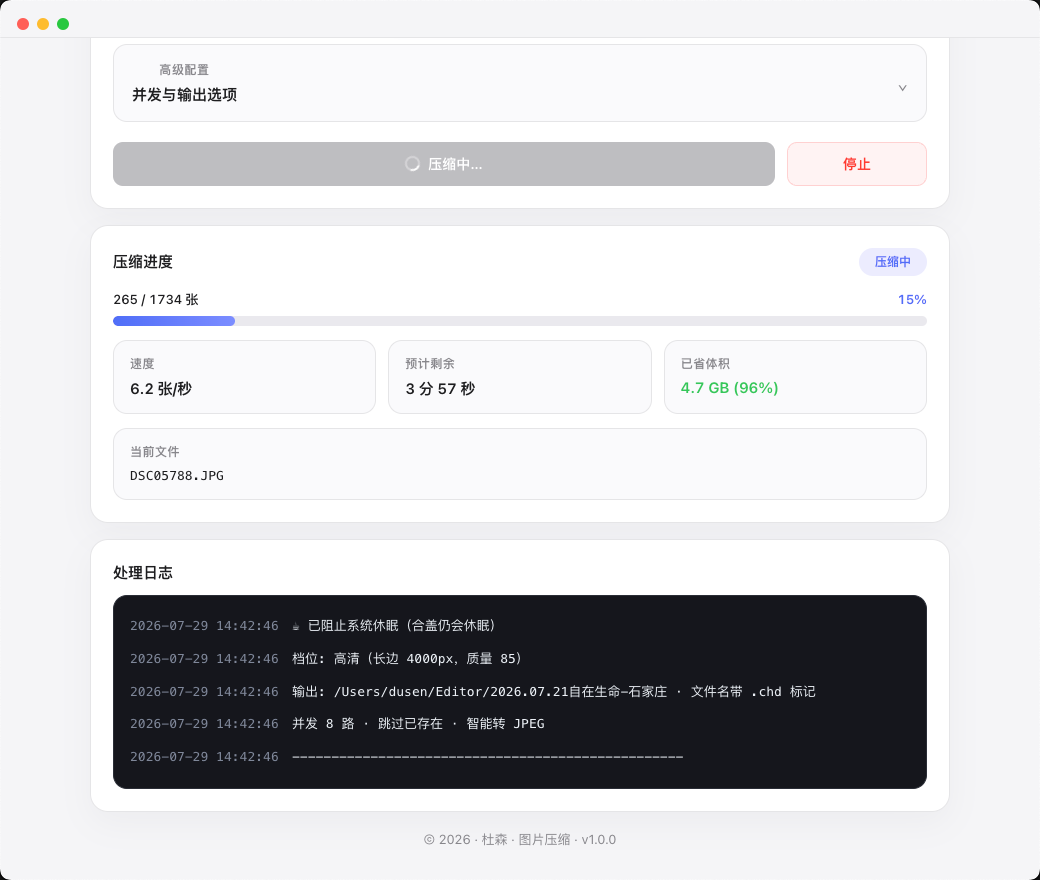
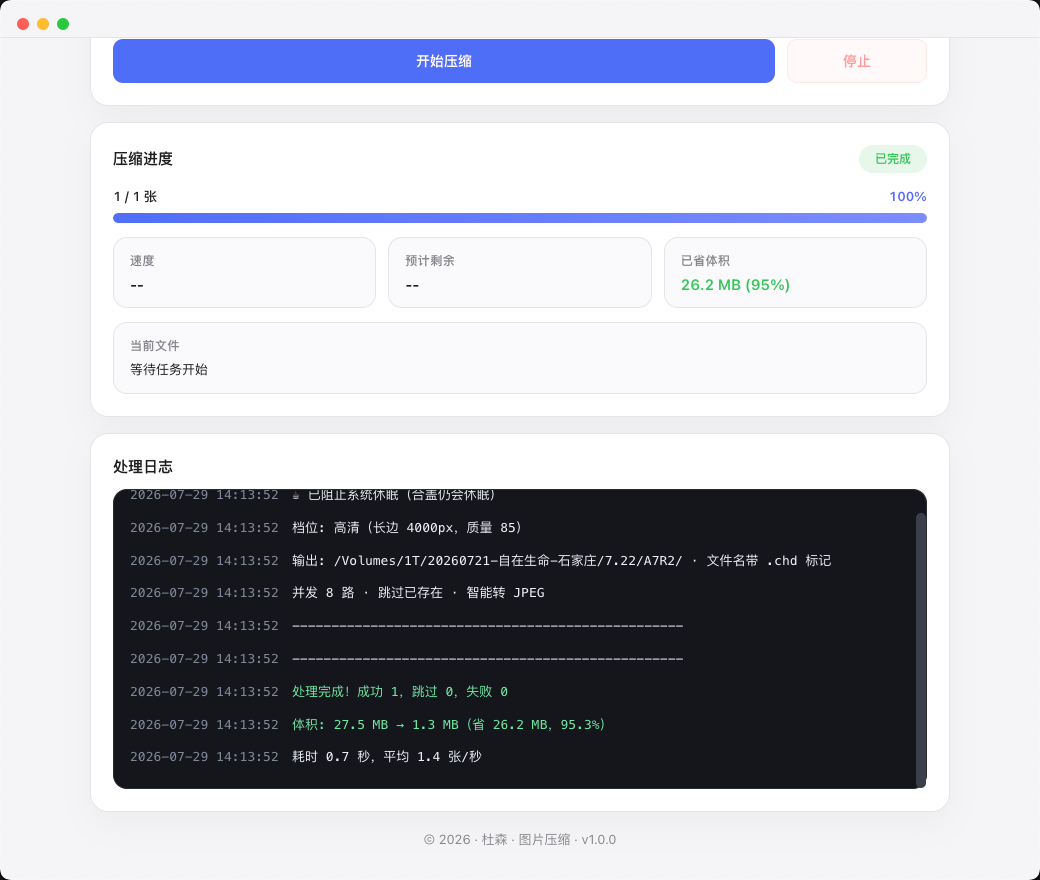
图片压缩
相机大图批量瘦身。超清 / 高清 / 标清三档,选之前就按你自己的图试压推算,直接告诉你压完多大、能省多少。整个目录扔进去就行——实测 1734 张 30.3 GB 的素材压到 1.4 GB,省 95%,每秒 6 张。拍摄参数(EXIF)原样保留,压过的自动跳过。
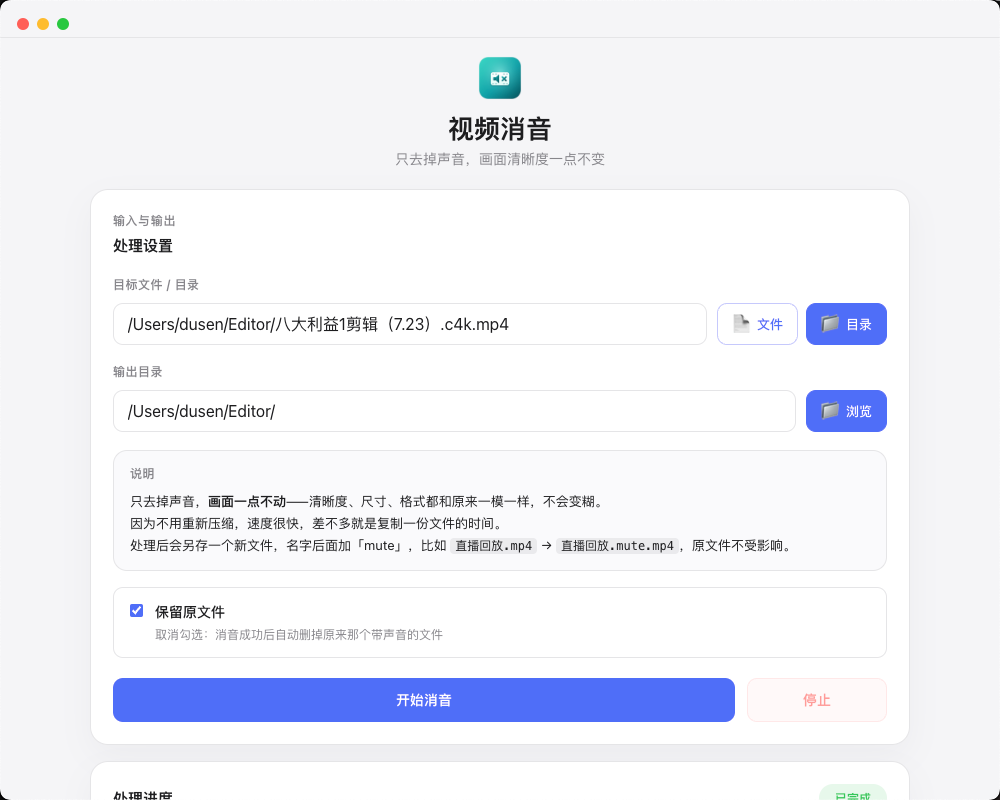
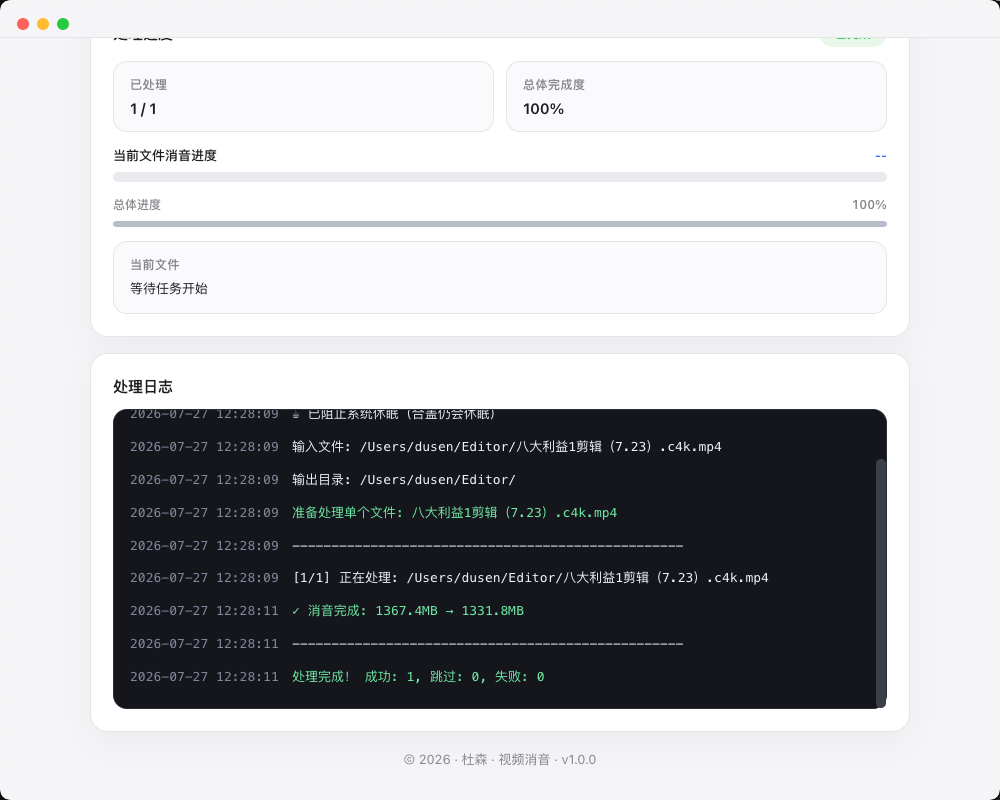
视频消音
只去掉声音,画面一点不动。视频流原样复制、不重新编码,清晰度、尺寸、格式和原来一模一样,速度差不多就是复制一份文件的时间。支持选目录批量递归处理,本来没声音的自动跳过,处理完还会再检查一遍音轨确实没了。

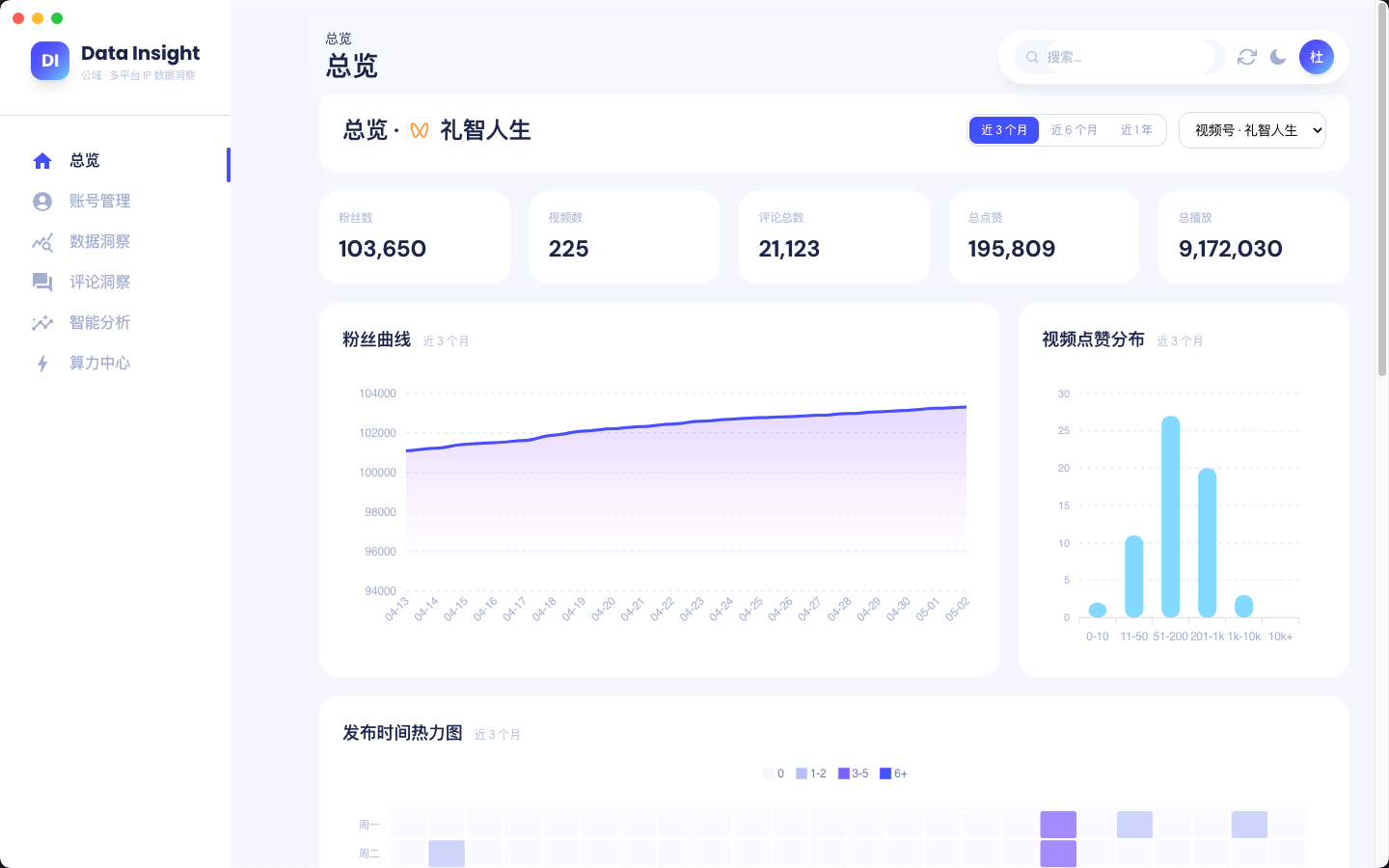
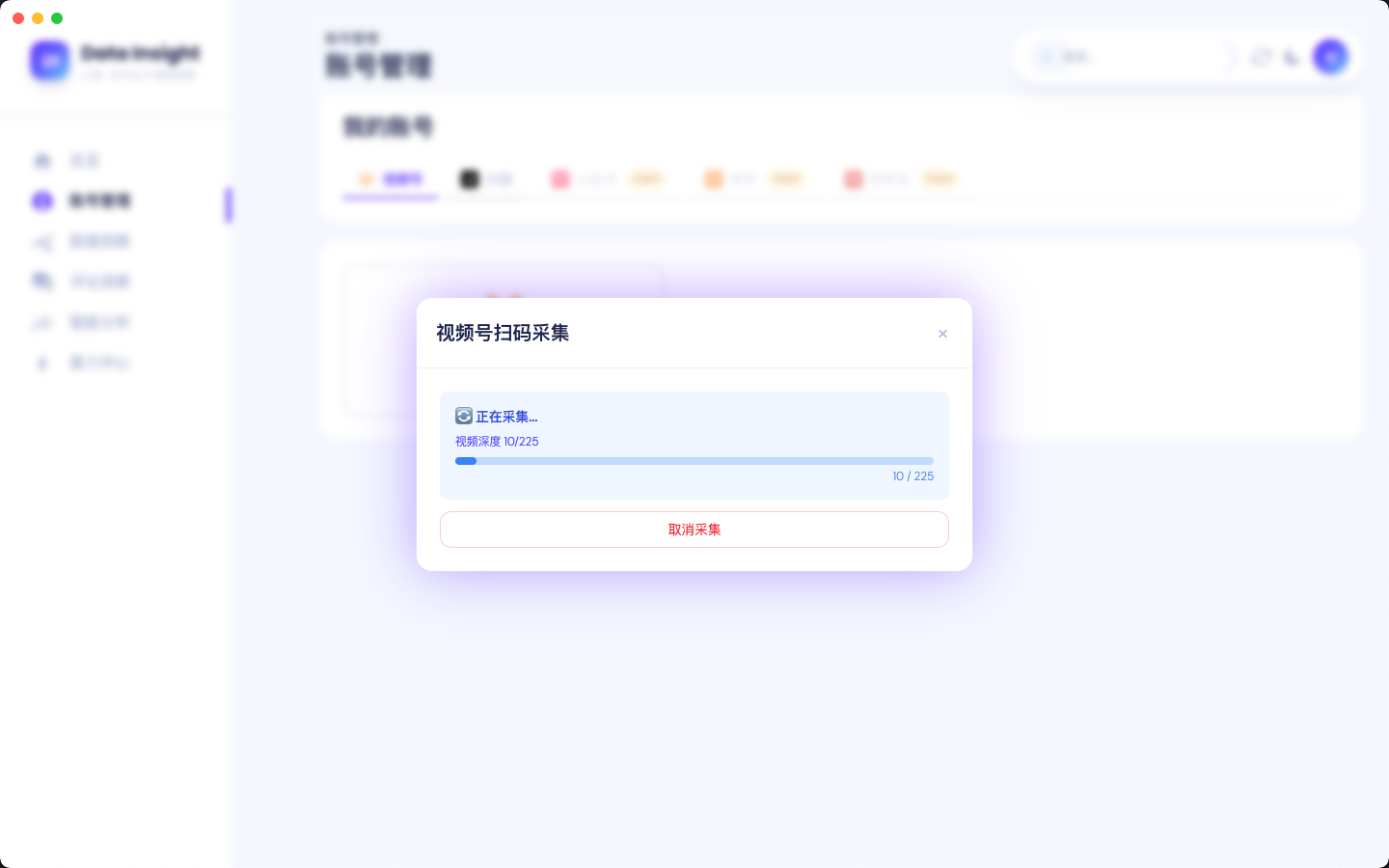
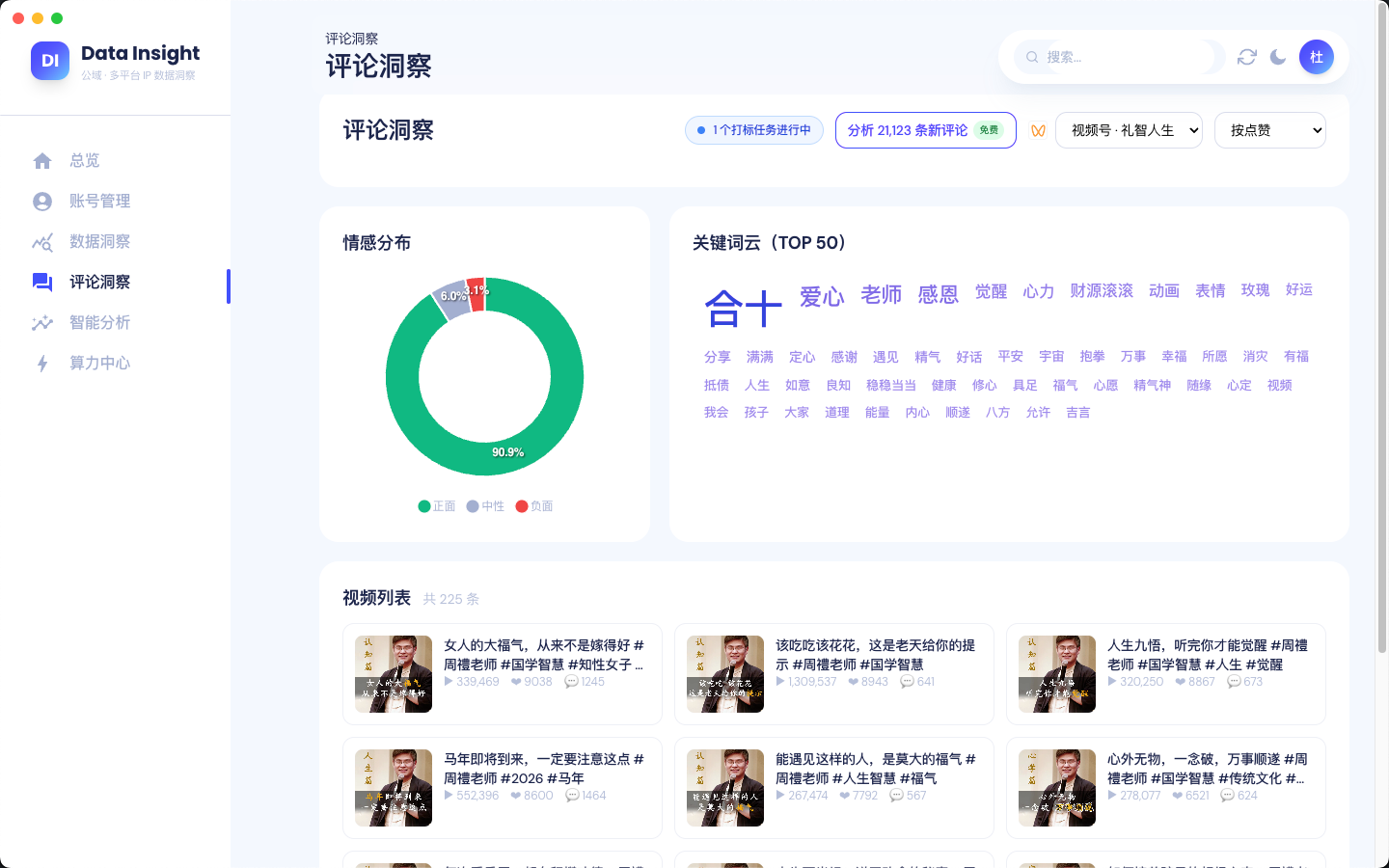
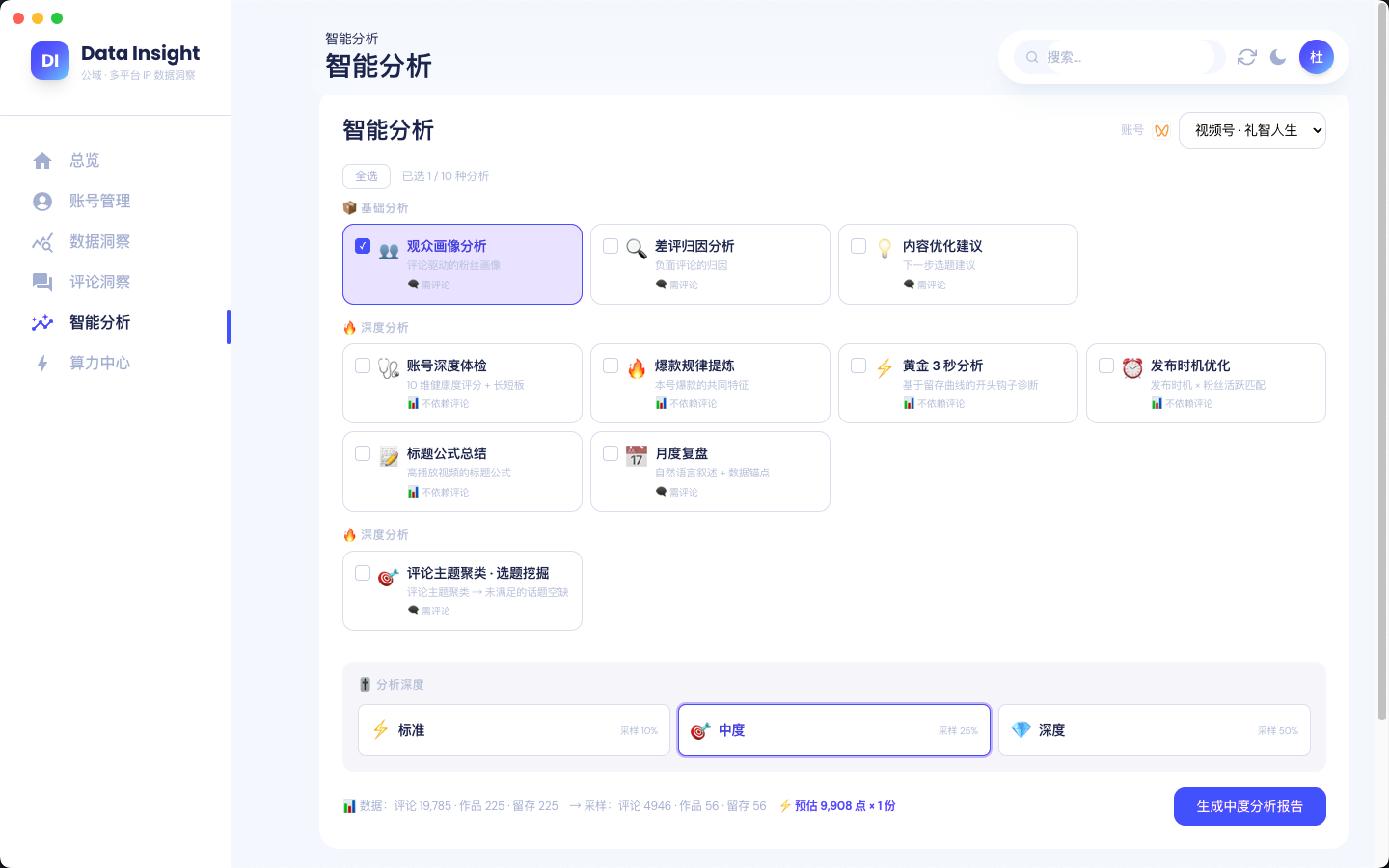
数据洞察
公域多平台 IP 数据洞察平台。一键扫码采集视频号 / 抖音账号数据,自动汇总粉丝、热评、互动与发布节律,再由 AI 给出观众画像、选题挖掘和内容优化建议。
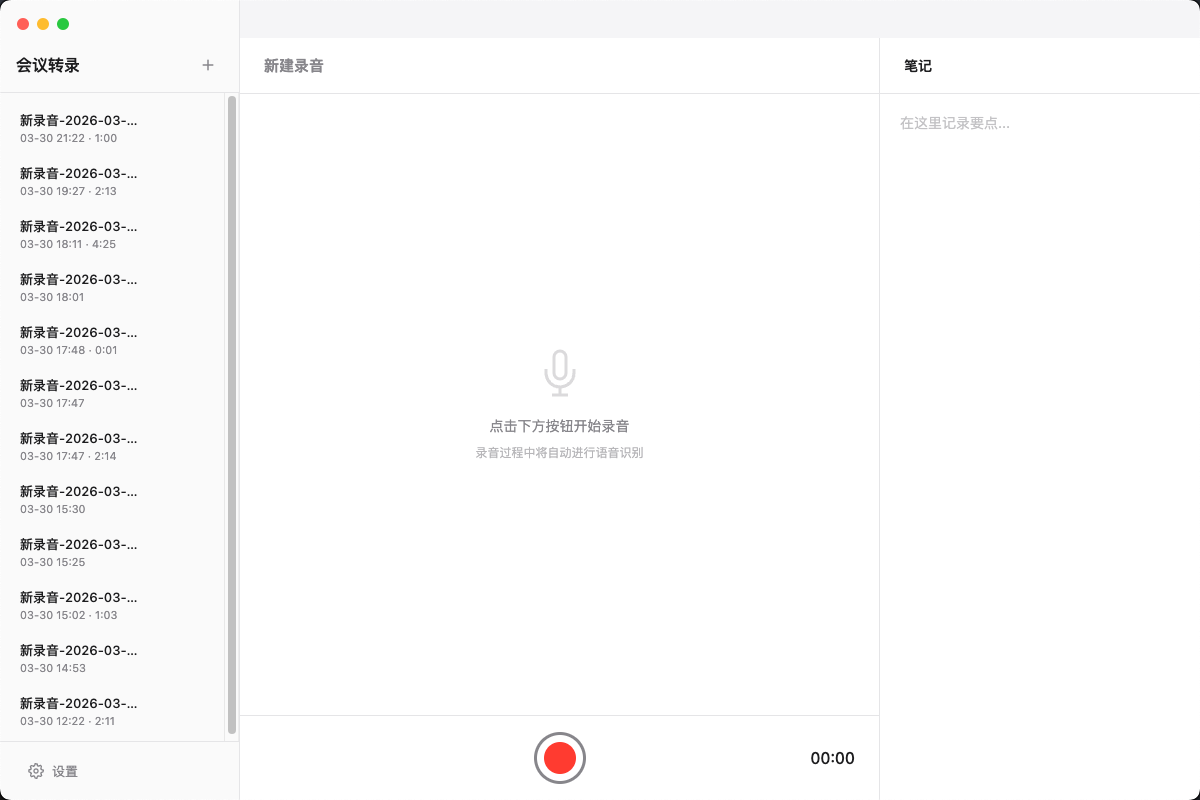
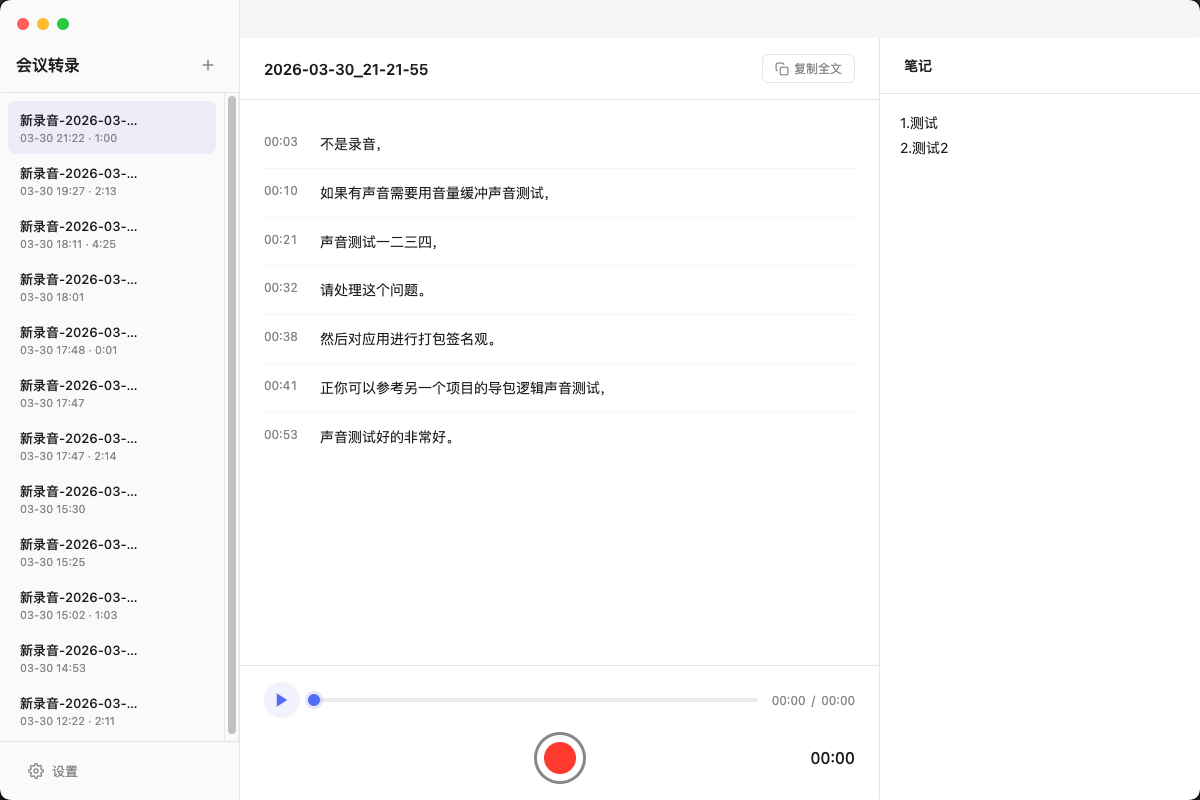
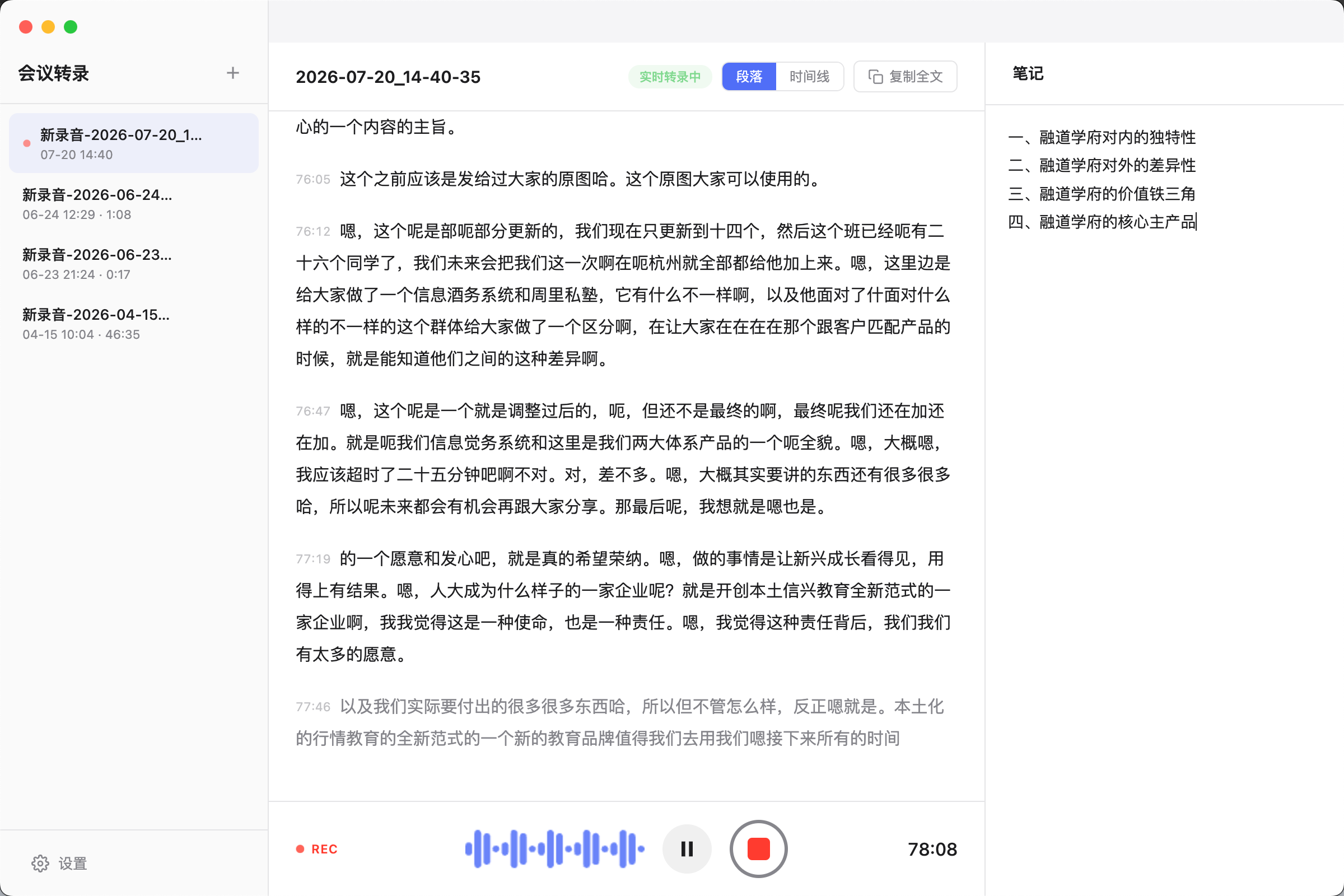
会议转录
实时会议转录桌面应用,边录边转成文字,同时支持记录会议笔记。适合开会、访谈、复盘等需要即时整理内容的场景。
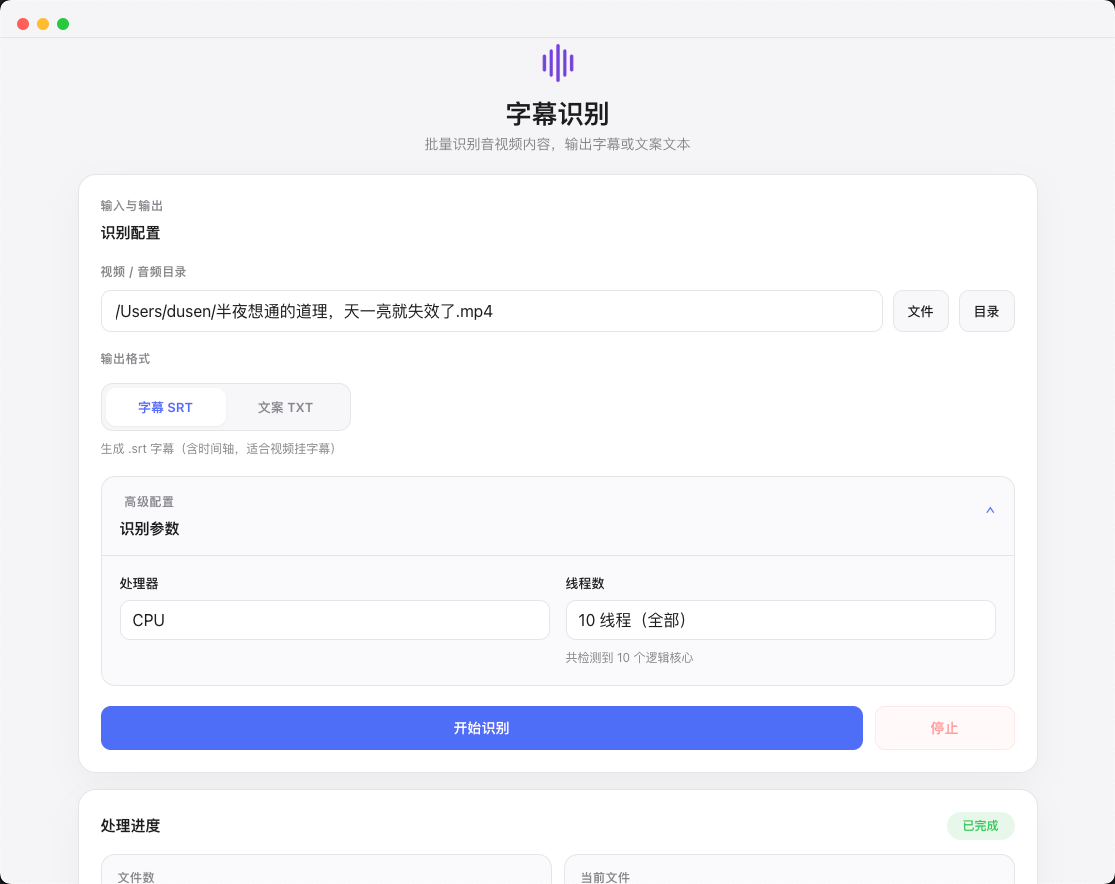
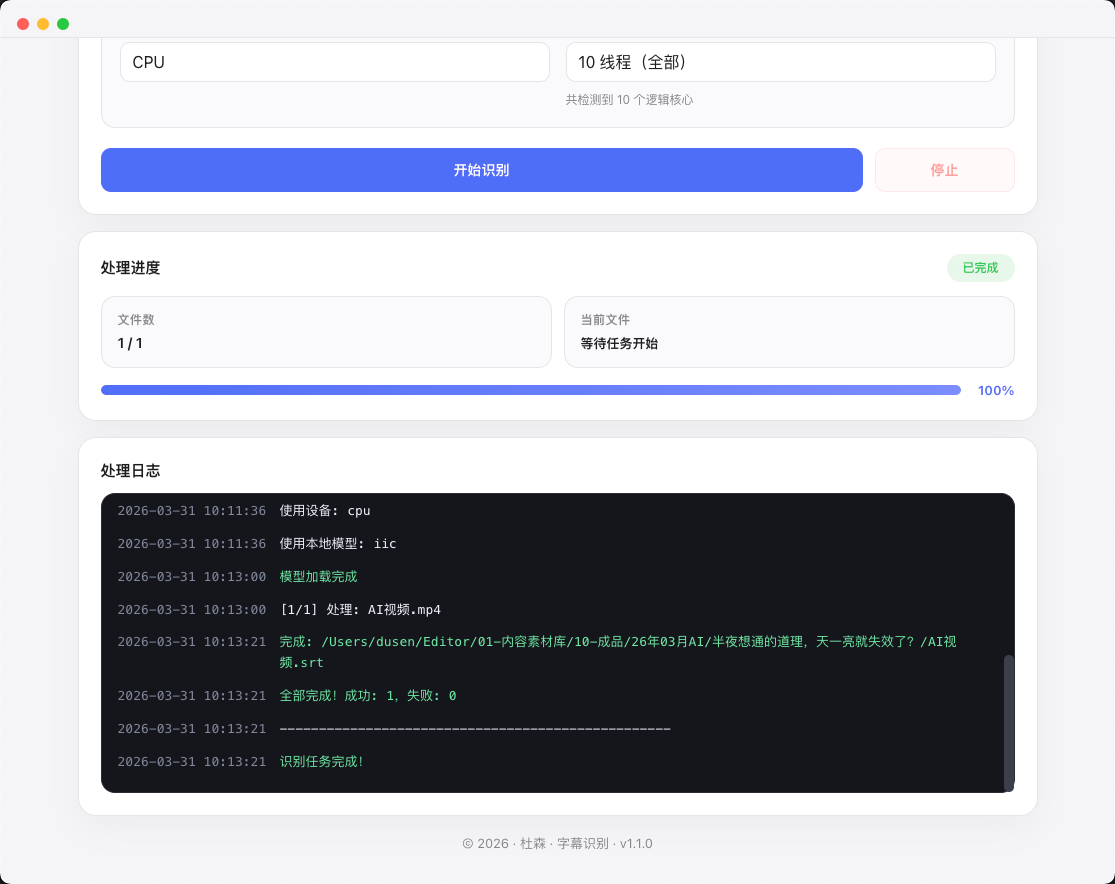
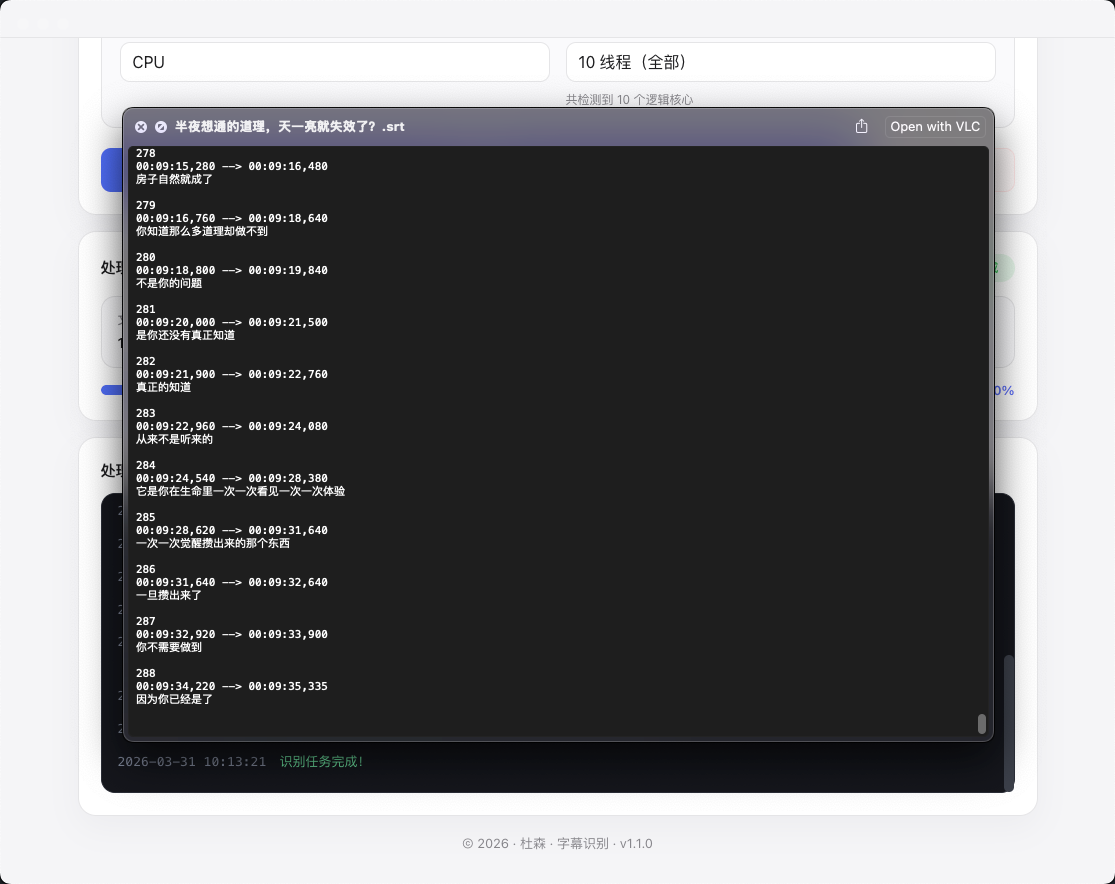
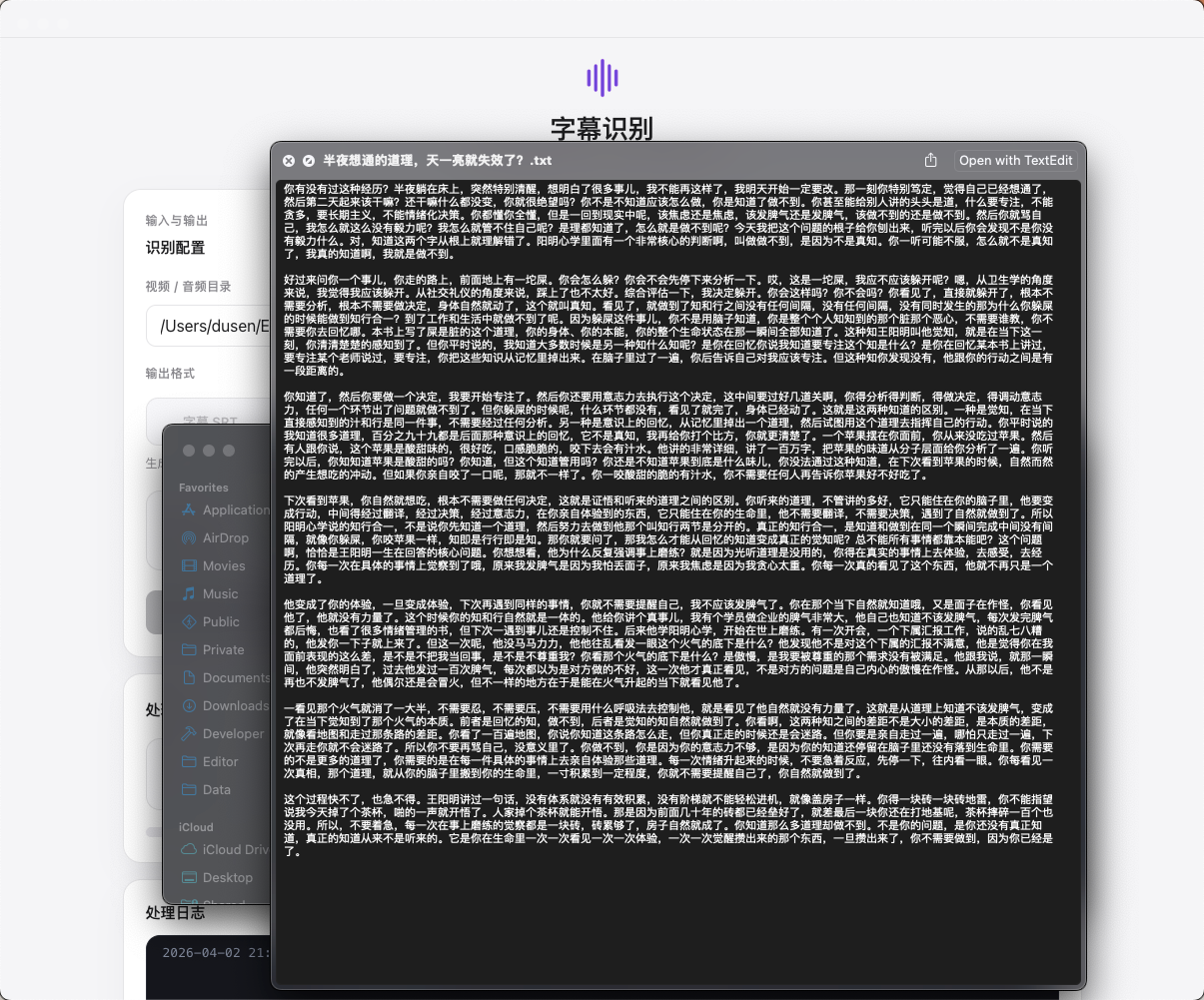
字幕识别
针对中文识别做了优化,支持视频和音频文件的语音转文字,自动生成带时间轴的字幕内容,适合内容整理和视频初剪阶段。
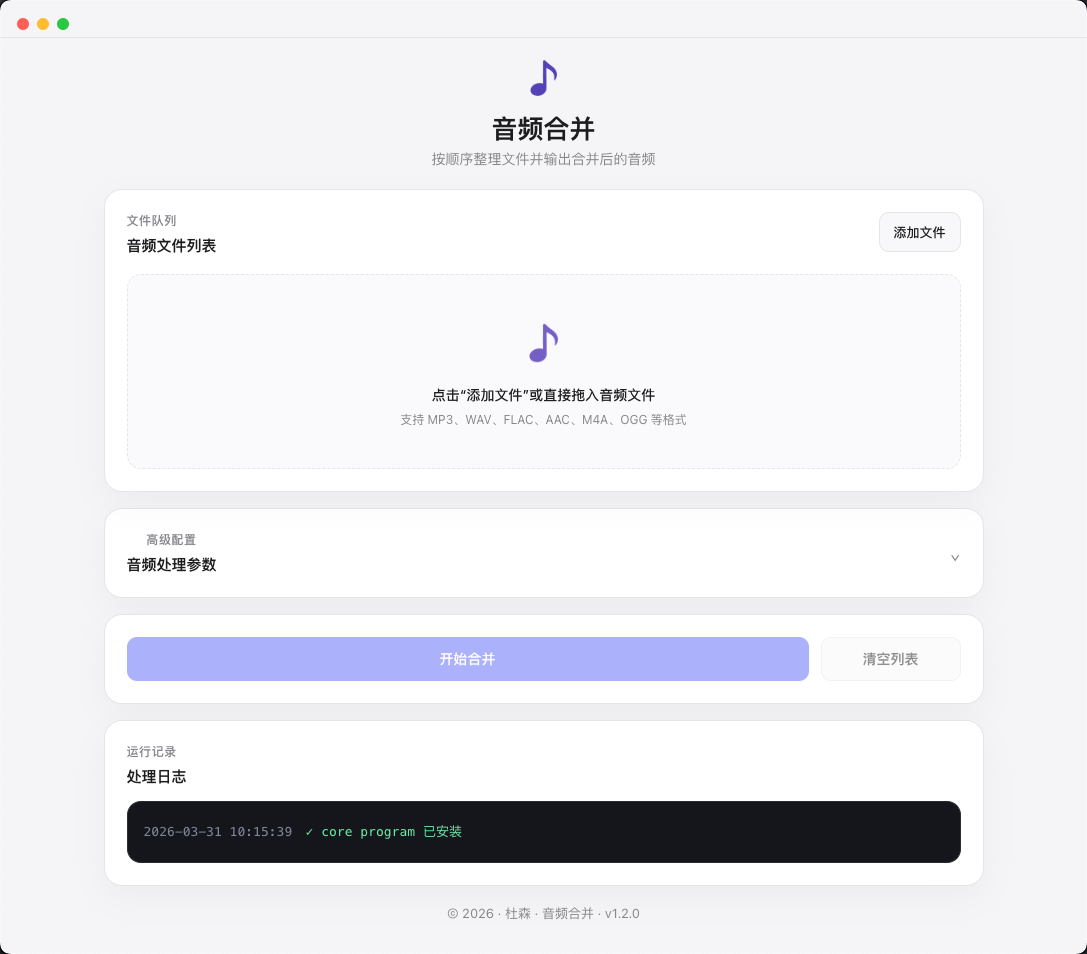
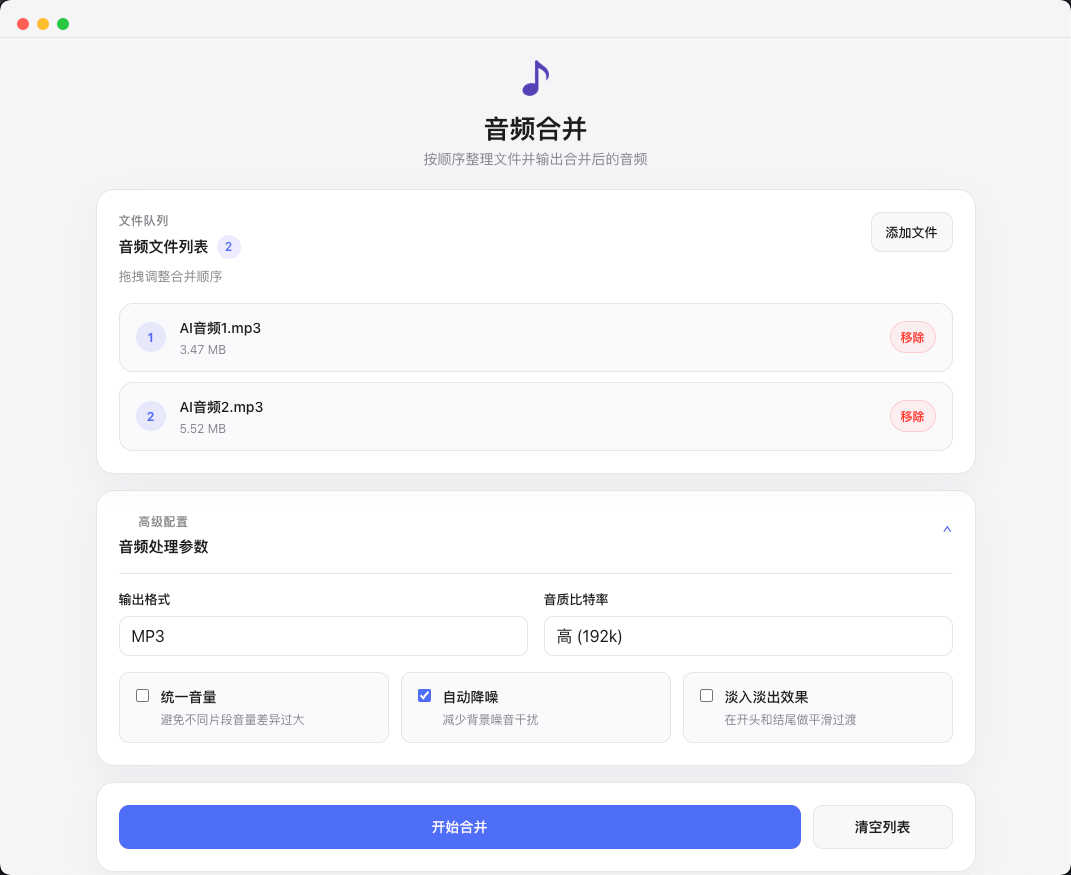
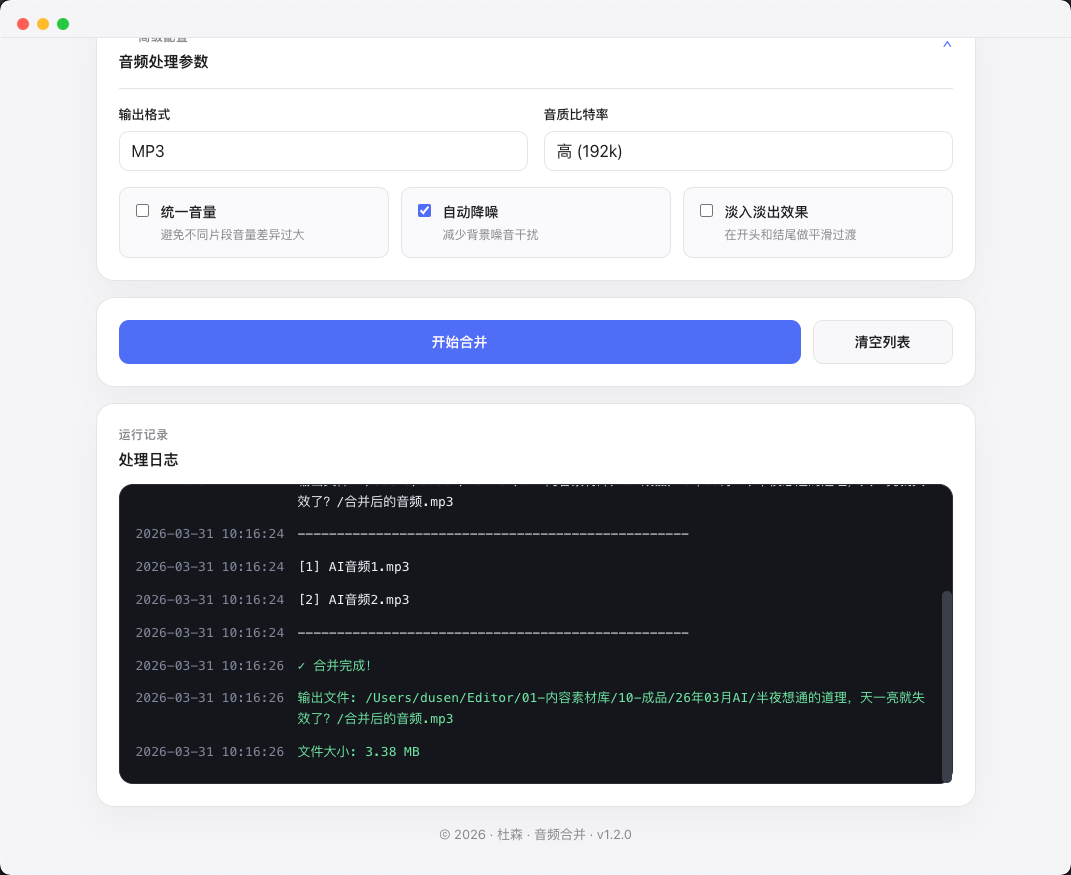
音频合并
通过拖拽整理文件顺序,快速合并多段音频。支持主流格式输入,还保留统一音量、降噪和淡入淡出等常用处理能力。
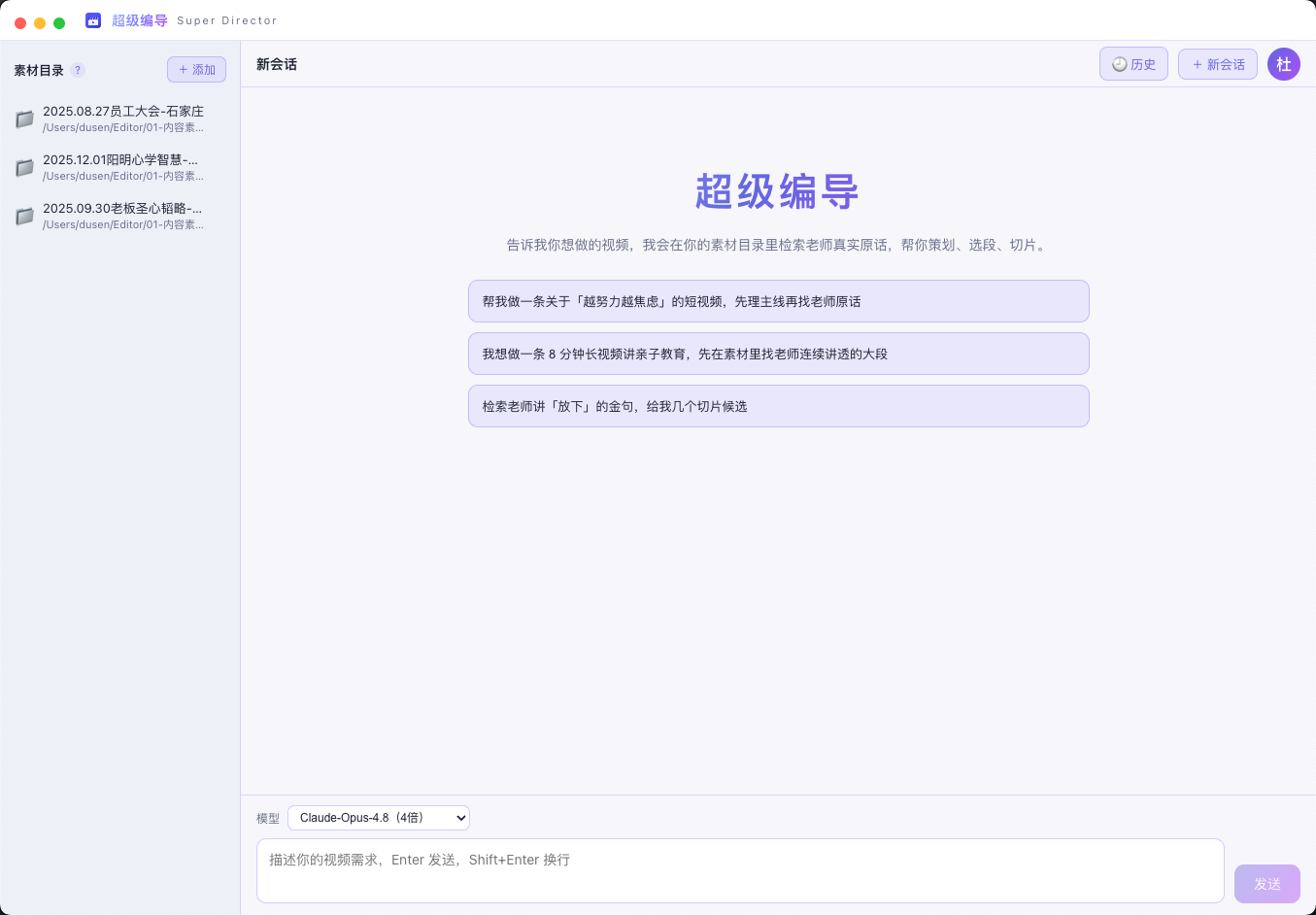
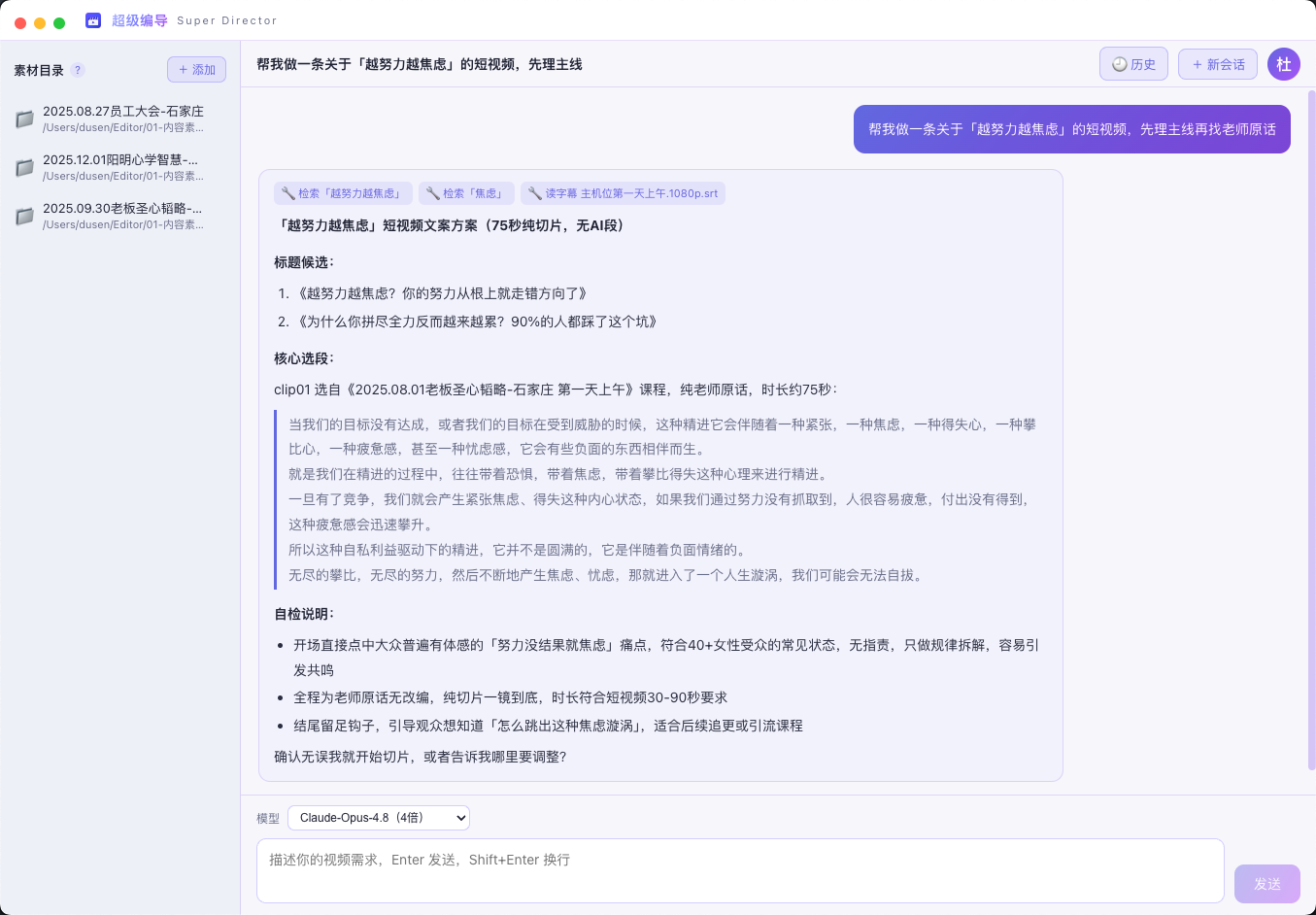
超级编导
懂国学切片方法论的对话式智能剪辑助手。选一个带字幕的素材库目录,像聊天一样说出你想做的视频,AI 从库里检索老师真实原话,帮你策划选题、选段、生成剪辑清单,一键粗剪出片段。
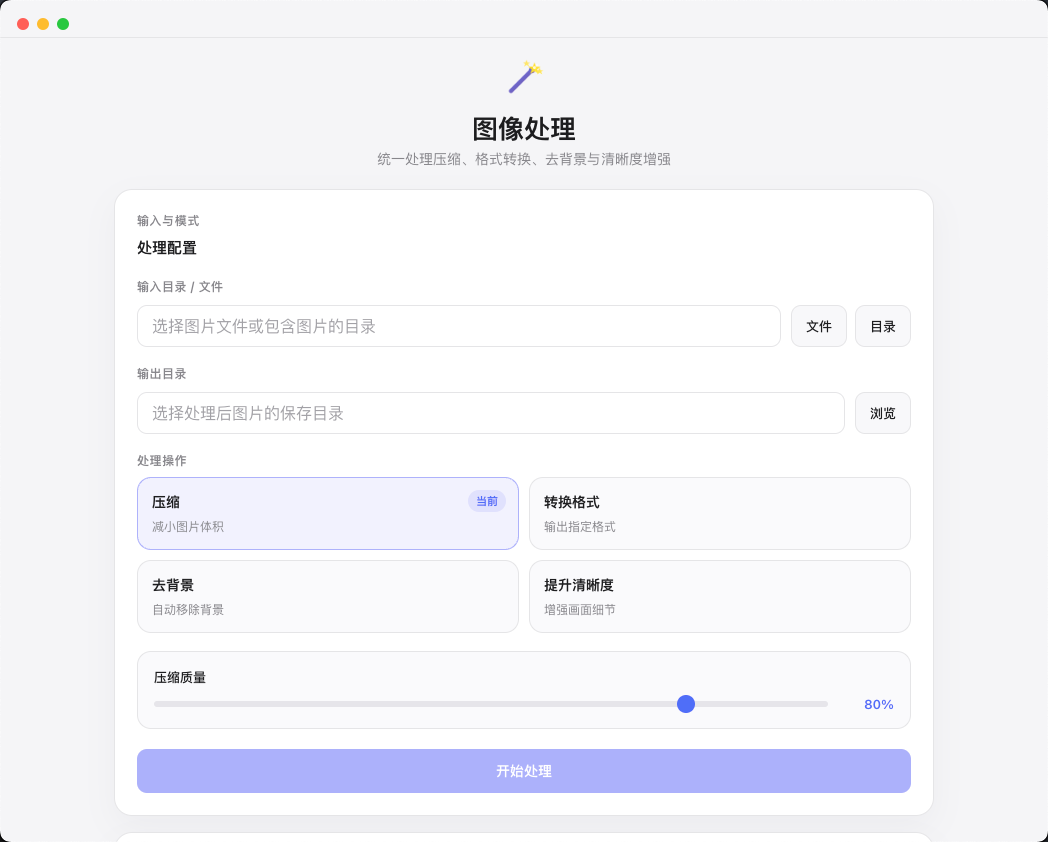
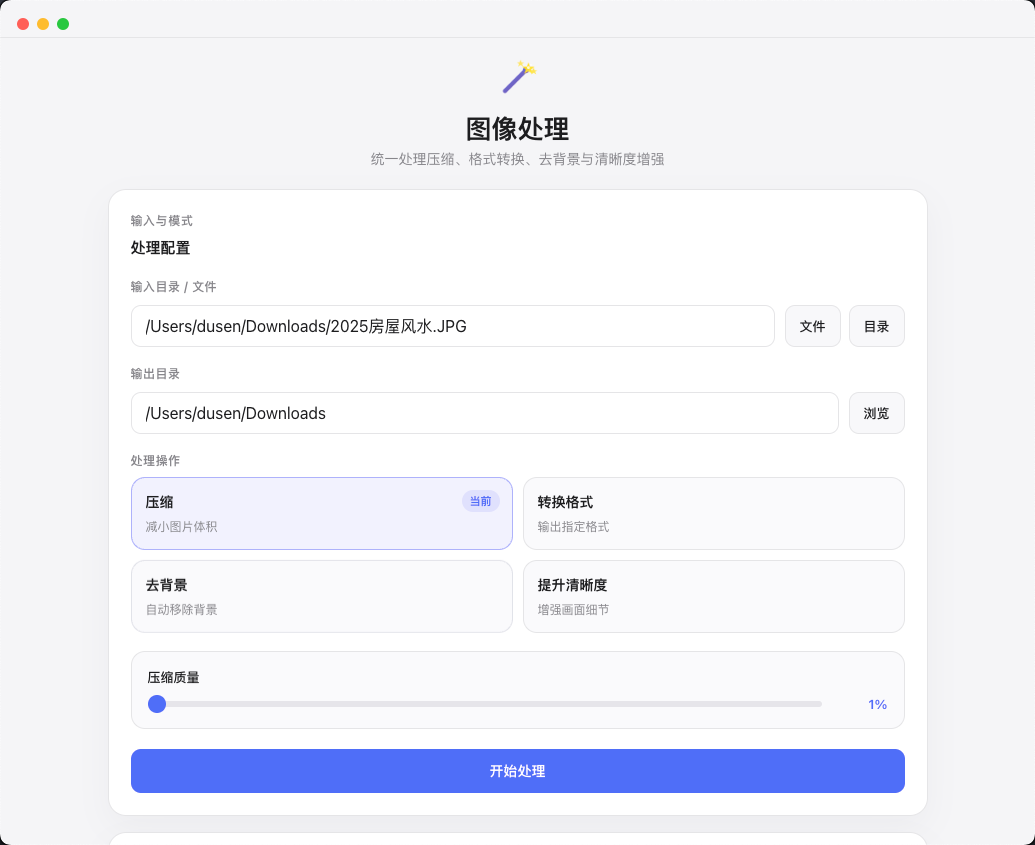
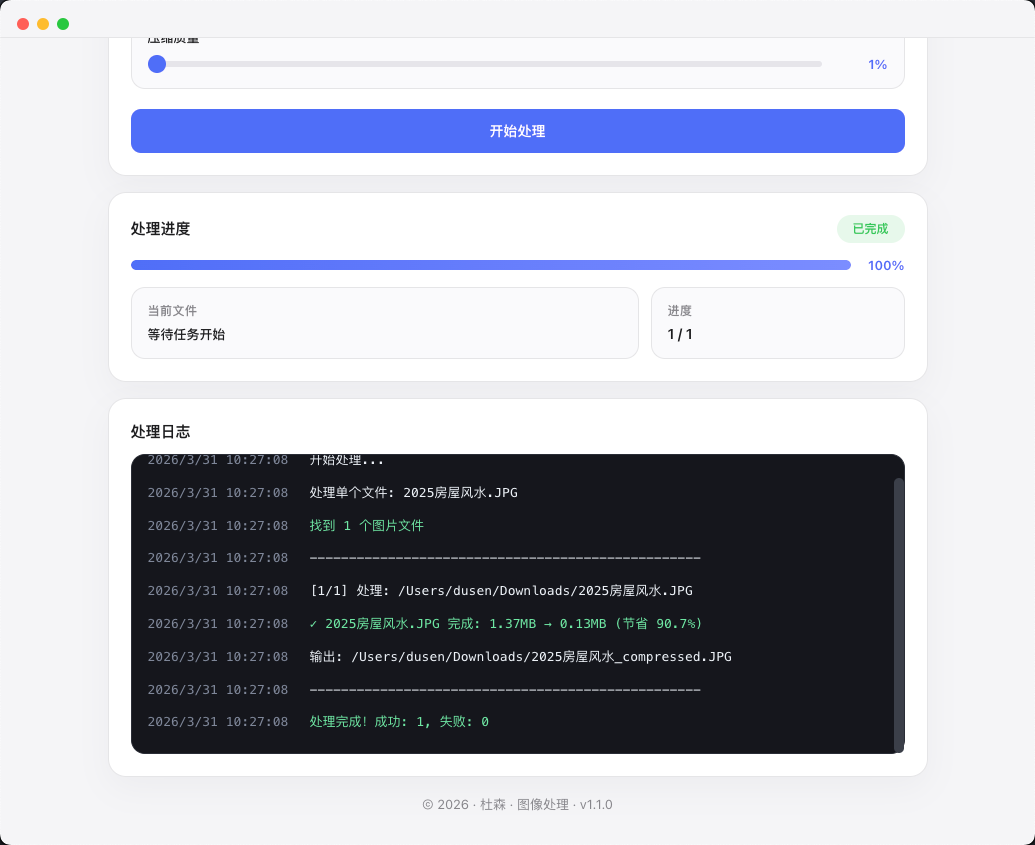
图像处理
压缩、格式转换、AI 去背景和清晰度增强集中在同一个工作台里,适合经常处理素材、导出多平台图片版本的设计和运营场景。
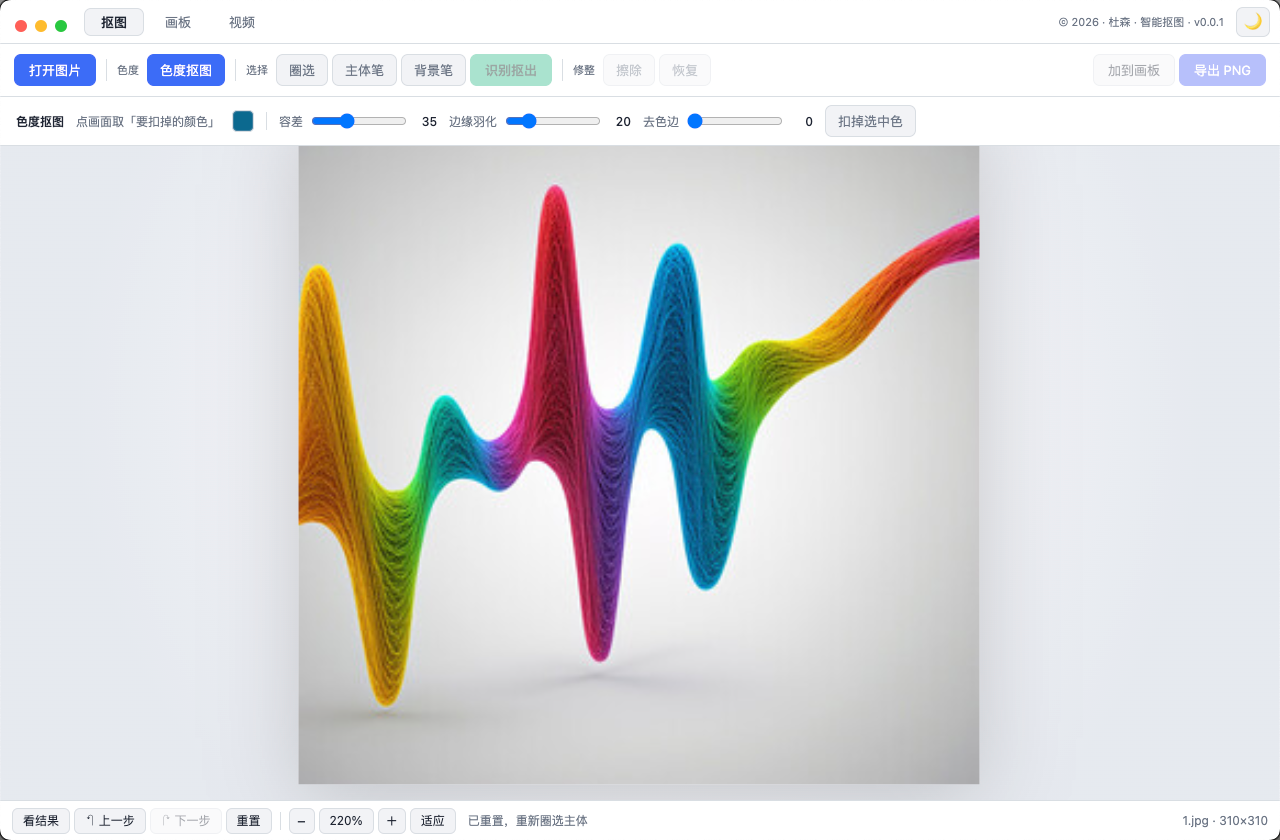
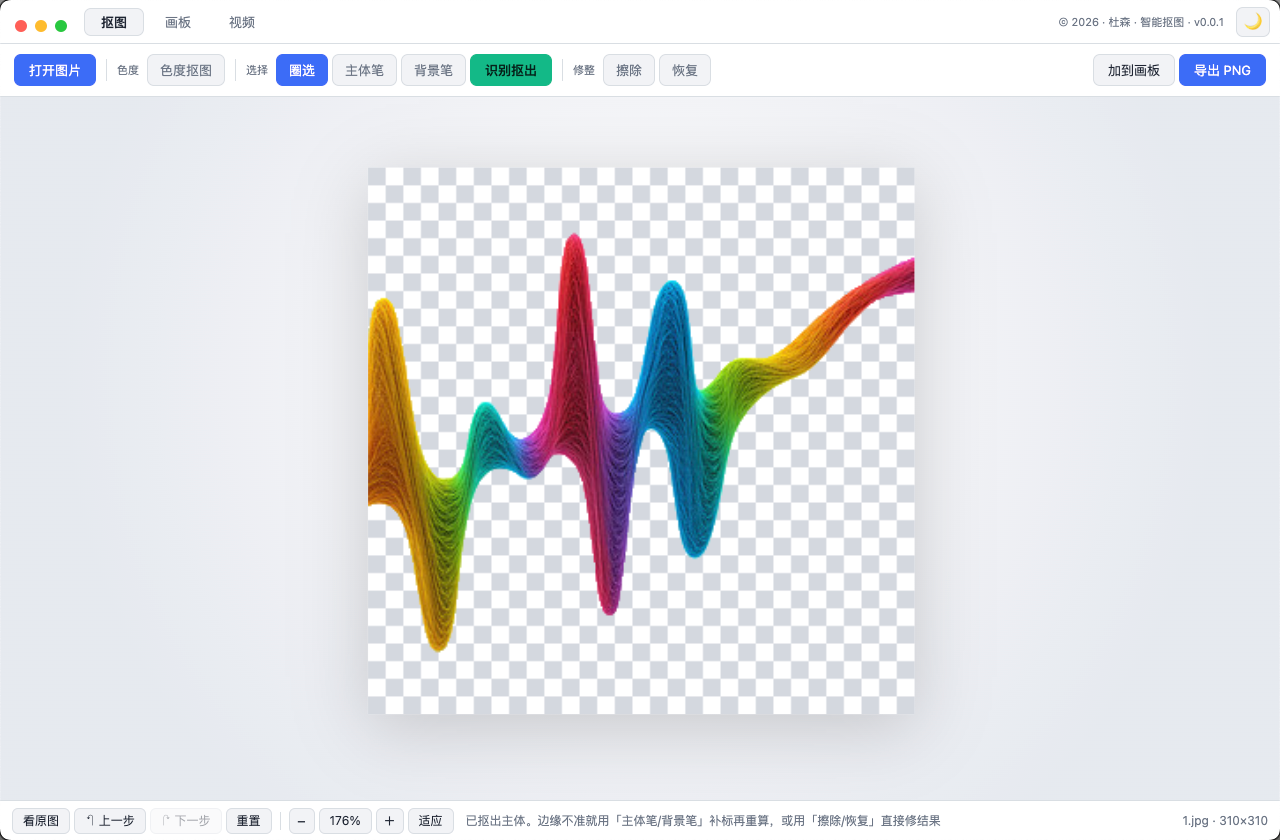
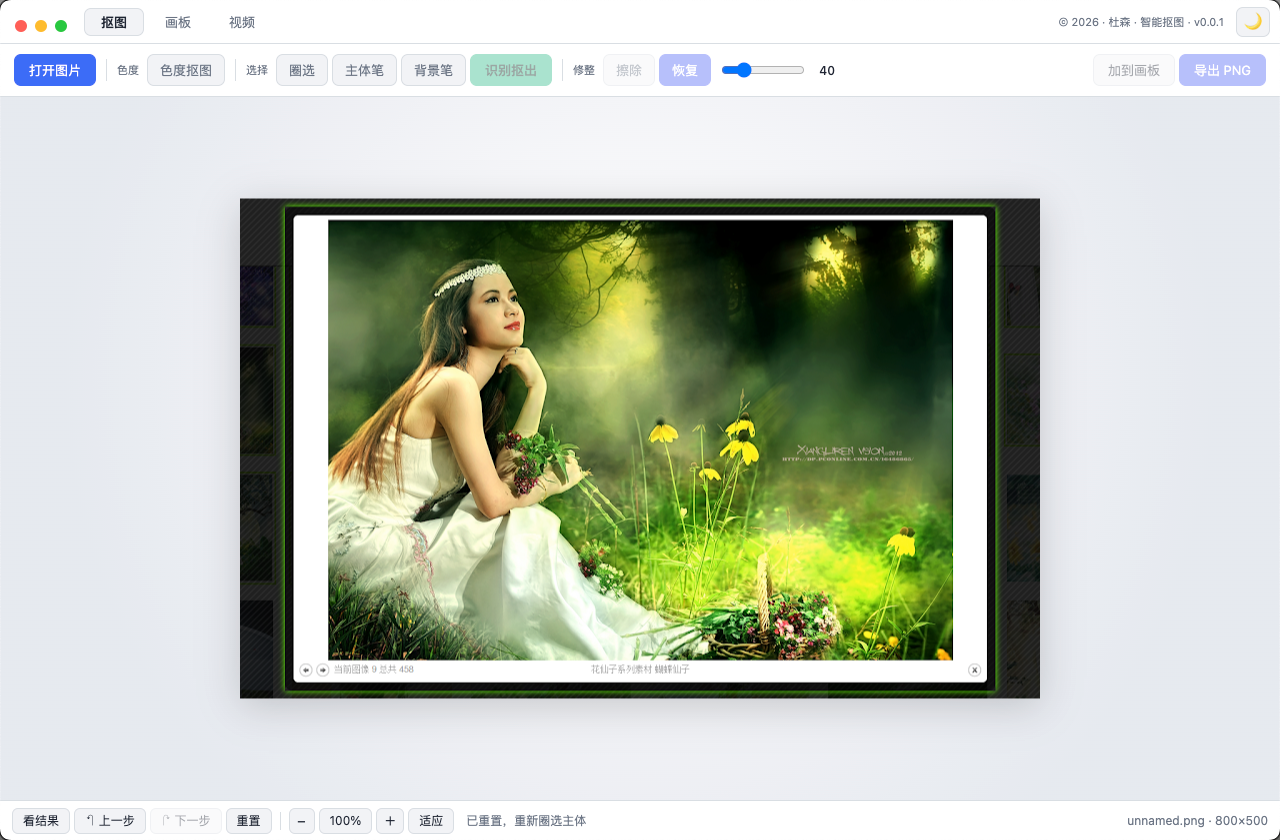
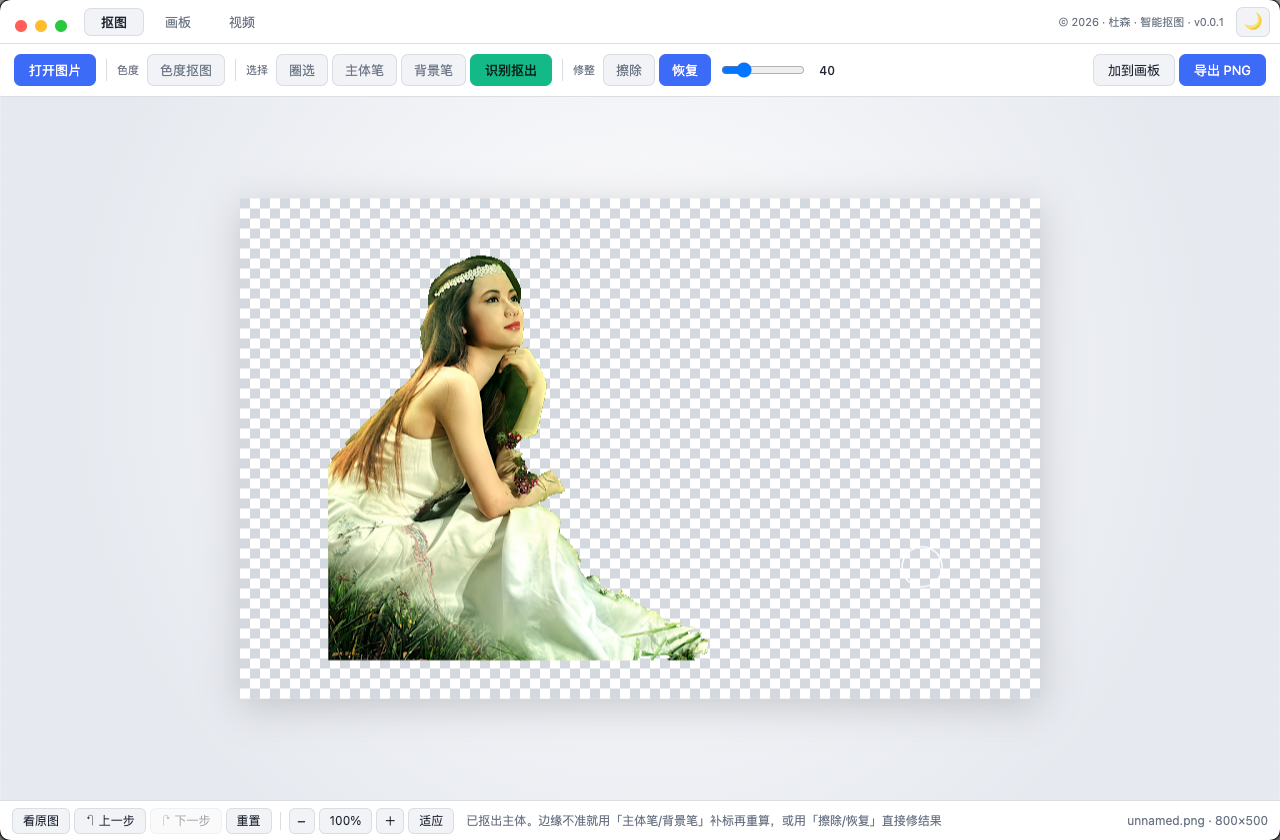
智能抠图
圈一下主体自动识别边缘,或点背景色一键抠掉,导出透明 PNG。绿幕/纯色背景秒抠,杂乱背景用圈选 + 主体/背景笔精修;还能在画板里把抠好的主体摆到新背景上合成,视频也支持色度抠图。全程本地处理、不上传。
觉得好用?赞赏支持
如果这些工具帮到了你,节省了你的时间,欢迎通过微信赞赏支持作者持续开发。
