
本系列博文致力于让广大零基础的吃瓜群众写出第一个爬虫程序!
Quick Start
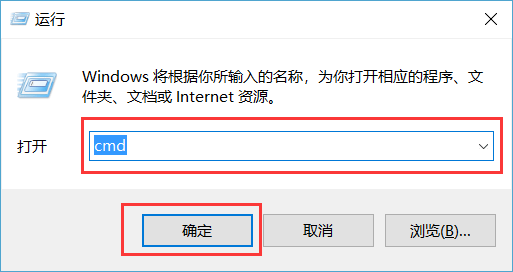
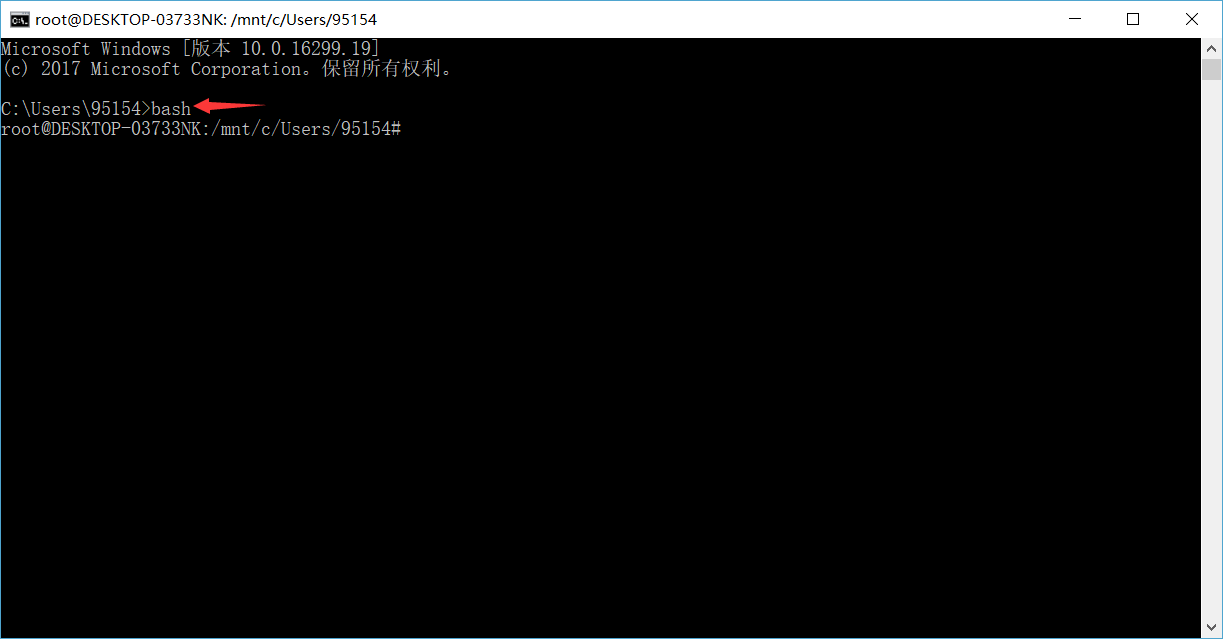
1. 使用快捷键 Win + R, 打开如下窗口, 输入 cmd, 然后点击确定. 接着在打开的窗口中输入 bash ,最后按回车键
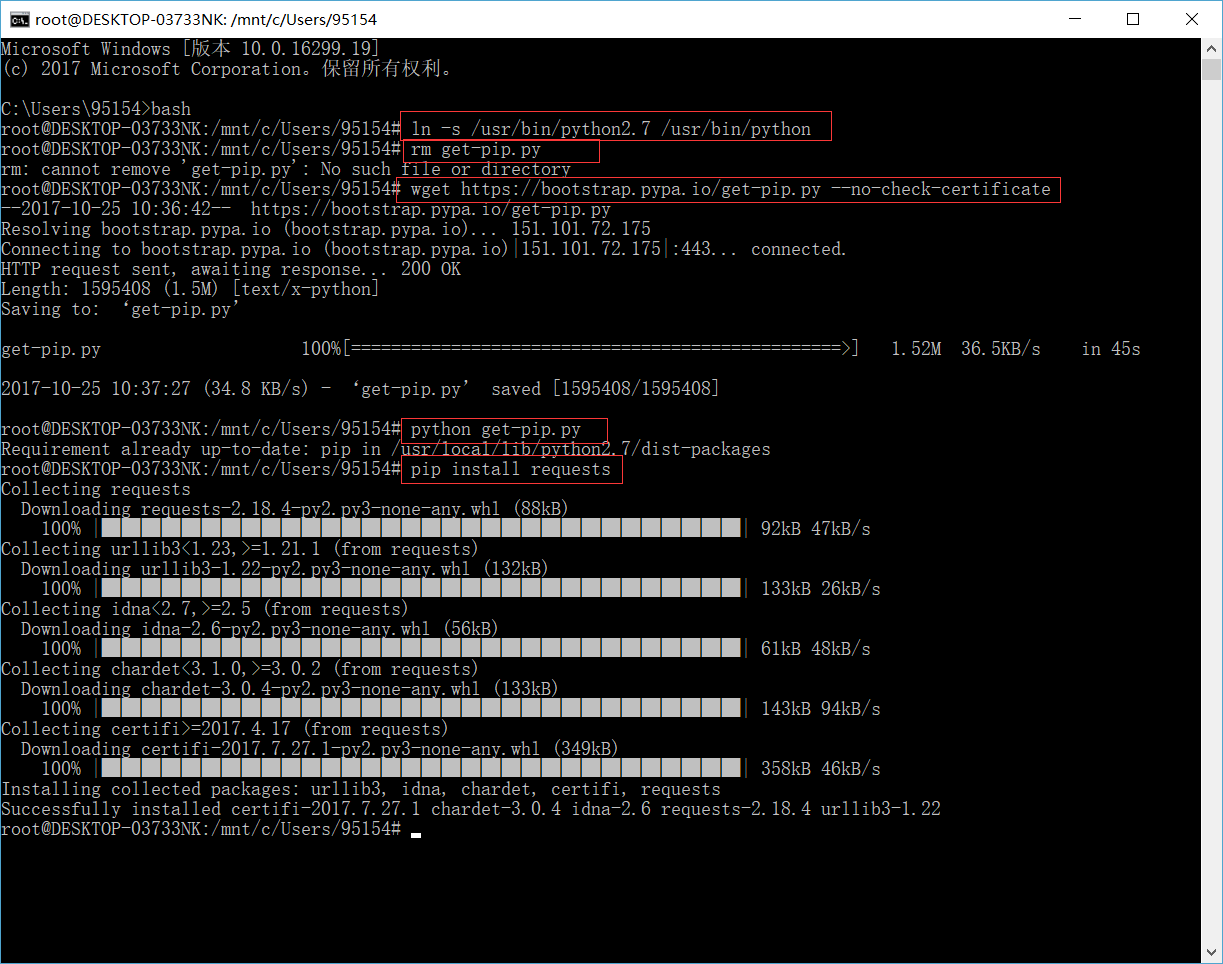
2. 把下列命令依次复制粘贴到窗口中, 并按下回车键
$ ln -s /usr/bin/python2.7 /usr/bin/python
$ rm get-pip.py
$ wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate
$ python get-pip.py
$ pip install requests
tips:
- 上面这几行命令是为第一次写爬虫做的准备工作, 这些命令只用执行一次, 以后这一步跳过即可.
- 关于复制、粘贴:这个黑底白字的窗口 复制与粘贴的方式和平时用的不太一样。复制:先用鼠标在窗口选中需要复制的内容,然后按回车键 这样就复制成功了。粘贴:在窗口中鼠标右键,即可把复制的内容粘贴进去。第一次用这种方式复制粘贴想必内心是拒绝的😂
- 如果执行过上面的命令, 以后想进入 python 编辑环境, 就不用再输入 python2.7 , 可以直接输入 python 来召唤她! 「偷懒或懒惰促进了社会的进步,科学的发展」 🤔
3. 输入 python ,点击回车。
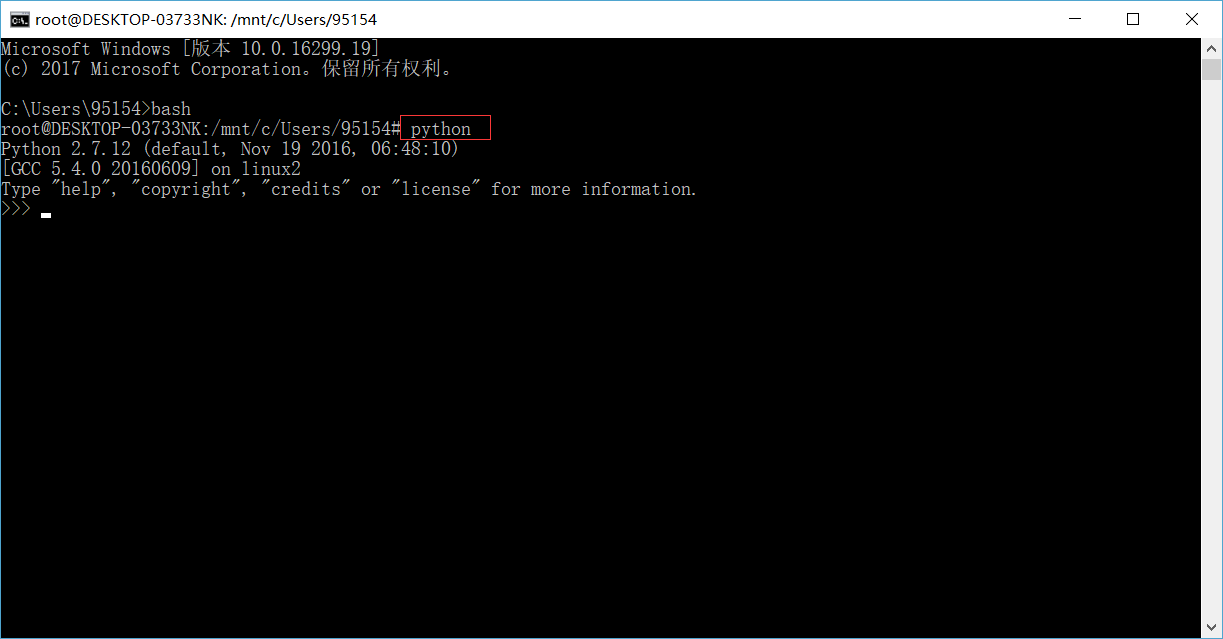
4. 现在我们已经进入到python的世界,接下来我们就可以开始编写爬虫程序了😃😜☕
$ import requests
$ request_url = 'https://www.baidu.com/'
$ html_doc = requests.get(request_url).content
$ print html_doc
上面这几行代码,会把下面这张图片中的内容抓取出来👍

这样我们就完成了一个简单的爬虫小程序了😎
接下来我来解释下刚才的代码的意思:
- "import requests" : 导入一个名叫 'requests' 的包. 简单来说, 就是拉来一个能帮我们干活(爬虫)的工具.
- "request_url = 'https://www.baidu.com/'": 声明我们要通过爬虫抓取哪个网站. 后面换上你想抓的网址链接, 大部分情况你都可以得到自己想要的
- "html_doc = requests.get(request_url).content": 帮我们干活的工具也有了, 想抓的网址也有了. 万事俱备只欠东风. 那这段代码就是帮我们去实现梦想了!
- "print html_doc" : 最后这个想必大家都比较熟悉, 类似于 print 'hello world!'. 就是把结果打印出来.


以上就是一个简单的小小爬虫, 是不是非常简单呢😜
大家如果对爬虫非常感兴趣, 可以看下官方是怎么玩转爬虫的, 想必会有更多收获哦👯
快速上手: http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
高级玩法: http://docs.python-requests.org/zh_CN/latest/user/advanced.html#advanced